HTTP의 역사
카테고리: networkJune 07, 2022
HTTP란 무엇인가?
HTTP는 Hypertext Transfer Protocol의 약자로, 이름에서 알 수 있듯이 처음엔 하이퍼텍스트 문서(링크를 통해 서로 다른 문서들을 연결한 문서)를 주고받기 위해 설계된 프로토콜입니다. 그래서 최초의 HTTP 버전은 오직 HTML 문서만 주고 받을 수 있었습니다.
하지만 사람들이 HTTP를 사용하다 보니, “HTML 말고 다른 이미지 같은 데이터도 주고 받을 수 있을 것 같은데?” 라고 생각하여 이후의 HTTP 버전에선 실제로 여러 타입의 데이터를 주고 받을 수 있게 되었습니다. 그래서 사실 현시점에서 생각해보자면 HTTP의 “H”는 큰 상관관계가 없다고 할 수 있습니다.
또한 일반적으로 HTTP는 TCP/IP 프로토콜 위에서 동작하는데, 사실 굳이 TCP가 아니어도 됩니다. 엄밀히 말해 HTTP는 TCP 뿐만 아니라 “reliable”한 프로토콜이면 무엇이든지 상관없습니다. 실제로 HTTP/3는 UDP를 기반으로 동작하는 QUIC 프로토콜을 기반으로 동작합니다.
HTTP의 역사
HTTP는 1989년에 Tim Berners-Lee 선생님을 필두로 CERN 기관의 연구자들이 개발하였습니다. 연구원이다 보니 논문을 읽을 일이 잦았는데, 논문이 단순한 텍스트로 되어 있어 논문에 첨부된 참고 문헌을 일일이 찾아 읽는 것이 번거롭다는 문제가 있었습니다. 이러한 문제를 해결하기 위해 문서를 링크로 연결할 수 있는 HTML 이라는 문서 양식을 개발하였고 네트워크를 통해 이 HTML을 주고 받을 수 있도록 고안한 프로토콜이 바로 HTTP 입니다. 여담으로, 하이퍼 텍스트라는 개념은 1960년대 부터 있었지만 당시에는 기술의 한계로 이를 구현할 수 없었고 80년대에 인터넷이 발전하면서 비로소 이를 구현할 수 있게 되었다고 합니다.
HTTP/0.9
1991년에 나온 최초의 HTTP 명세로, 0.9라는 버전 명은 원래부터 있었던 것은 아니고 이후에 붙여진 것입니다. TCP/IP 위에서 동작하고 기본 포트는 80번을 사용하는, GET 요청만 사용할 수 있는 아주 단순한 프로토콜로서, 클라이언트가 서버에 요청하면 서버는 HTML 형식의 메시지를 응답한 뒤 연결을 종료하는 형태로 동작한다고 명시했습니다.
HTTP/0.9의 요청 형식은 아래와 같이 GET 자원경로↵ 뿐이었으며, 이때 ↵는 캐리지 리턴(optional)과 라인 피드를 나타냅니다:
GET /page.html↵또한 요청은 idempotent(즉, 동일한 요청에 대해 항상 동일한 응답을 리턴)한 특성을 가지며, 연결이 종료된 이후에 서버는 요청에 관한 어떠한 정보도 저장하지 말 것을 명시하고 있습니다. 이것이 바로 HTTP가 “stateless”한 프로토콜이라 불리는 이유이죠! 그리고 심지어 0.9버전에선 HTTP 헤더조차 존재하지 않았습니다.
HTTP/1.0
HTTP/0.9가 나온 이후로 수많은 사용자들이 HTTP를 사용했지만, 기능이 매우 제한적이었기 때문에 대부분의 웹 서버들은 0.9버전 스펙에는 명시되지 않은 여러 기능들을 자체적으로 구현하여 사용하고 있었습니다. 이에 1996년 5월, HTTP Working Group에서 이러한 기능들을 문서화하여 발표하였는데 이것이 바로 HTTP/1.0 입니다. 사실 HTTP/1.0은 새로운 기능을 정의하기보다는, 이미 기존에 사람들이 구현해서 사용하던 기능들을 모아 문서화한 것에 가깝습니다.
HTTP/1.0에서 추가된 기능을 살펴보면,
-
HTTP 헤더가 추가되었습니다.
- 헤더 이름, 콜론(:), 헤더 값으로 구성되며 헤더 이름은 case-insensitive 입니다.
-
HEAD,POST가 추가되었습니다.HEAD는 리소스를 다운받지 않고도 HTTP 헤더와 같은 메타 데이터를 요청할 수 있도록 한 메서드입니다.POST는 클라이언트가 서버에게 데이터를 보낼 수 있도록 한 메서드입니다. FTP와 같은 프로토콜을 통해 서버에 직접 파일을 추가할 필요 없이, POST 메서드를 이용하여 파일을 포함한 여러 데이터를 전송할 수 있게 되었습니다.
- HTTP 요청에
HTTP/1.0과 같이 HTTP 버전을 명시할 수 있도록 하였습니다. 하위 호환성을 위해 버전을 명시하지 않으면 0.9버전으로 간주합니다. -
HTTP 상태 코드가 추가되었습니다.
- HTTP/0.9에선 에러를 HTML에 담아 전달했어야 했는데, HTTP/1.0에선 상태 코드를 통해 요청 성공·실패 등의 여부를 명시할 수 있게 되었습니다 (물론 이외에도 여러 정보를 명시할 수 있습니다).
HTTP/1.0 요청 및 응답을 예로 들면 아래와 같습니다:
GET /page.html HTTP/1.0↵
Header1: Value1↵
Header2: Value2↵↵
HTTP/1.0 200 OK
Content-Type: text/html
<html>
<p>Hello, world!</p>
</html>이때, 위에서 볼 수 있듯이 HTTP/1.0 버전의 응답은 HTTP 버전, 상태 코드, 상태 코드 설명으로 구성됩니다.
HTTP/1.1
1997년 1월에 최초로 HTTP/1.1 스펙이 공개되었으며, 이후 여러 차례 개정되었습니다. HTTP/0.9 스펙 문서가 약 700자로 구성되었던 것에 비해 HTTP/1.1은 약 100,000자로 1.1버전에 관한 내용을 상세히 다루려면 책 한 권을 써야 할 정도가 되었습니다.
따라서 HTTP/1.1에 추가된 내용을 간략히 살펴보자면,
HOST요청 헤더를 반드시 포함하도록 합니다.- 지속 연결 기능이 추가되었습니다.
- 파이프라이닝 기능이 추가되었습니다.
PUT,OPTIONS,DELETE등의 메서드가 추가되었습니다.- 캐시를 제어할 수 있는 메커니즘이 추가되었습니다.
- HTTP 쿠키가 추가되었습니다.
- 기타 등등…
여기선 HOST 헤더, 지속 연결, 파이프라이닝에 대해서만 살펴보겠습니다.
HOST 요청 헤더
HTTP 요청을 보낼 땐 https://www.google.com/index.html과 같은 절대 경로가 아니라 /index.html처럼 상대 경로를 명시합니다. 이는 HTTP가 만들어졌을 땐 웹 서버 하나당 오직 하나의 웹 사이트만 호스팅하고 있었기 때문에 굳이 절대 경로를 명시할 필요가 없었기 때문인데요, 하지만 요즘엔 가상 호스팅(virtual hosting)이라고 해서 하나의 서버에서 여러 개의 도메인을 호스팅할 수도 있습니다. 이 때문에 상대 경로뿐만 아니라 어떤 도메인에 접속하는지를 명시해줄 필요가 생겼고, 이전 버전과의 하위 호환성을 위해 절대 경로를 명시하는 방식 대신 HOST 헤더에 도메인을 명시하는 방식으로 구현되었습니다:
GET / HTTP/1.1
HOST: www.google.comHTTP/1.1에서 HOST 요청 헤더를 포함하지 않는 경우, 서버는 해당 요청을 무시해야 합니다. 물론 대부분의 서버가 HOST 헤더 없이도 알아서 잘 동작하도록 구현되어 있긴 하지만 HTTP/1.1을 사용하는 경우 HOST 헤더를 명시하는 것이 바람직합니다.
지속 연결
원래 HTTP는 요청할 때마다 새로운 TCP 연결을 생성하고, 응답을 마치면 연결을 종료하는 방식으로 동작합니다. HTTP로 전송하는 데이터가 많지 않았던 초창기엔 딱히 별문제가 없었지만, 웹이 발전하면서 웹 사이트 하나를 표시하는데 수십·수백 개의 자원을 요청하다 보니 이러한 방식이 문제가 되었습니다:
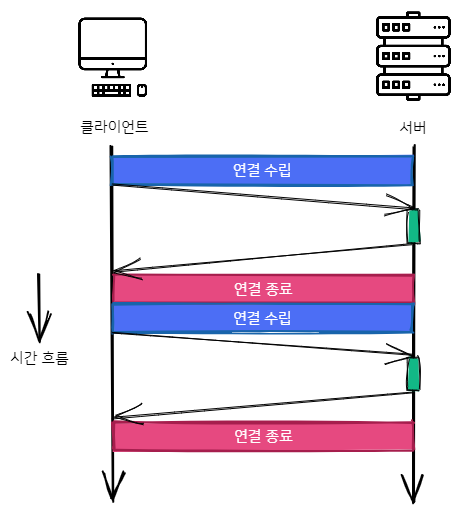
따라서 HTTP/1.1부터는 기존에 연결한 TCP 연결을 재사용하는 지속 연결 기능을 지원합니다. (사실 이 기능은 비록 스펙에는 포함되지 않았으나 HTTP/1.0 시절에도 지원하는 서버가 많았다고 합니다). 이 기능은 Connection 요청 헤더에 Kee-Alive라는 값을 명시함으로써 사용할 수 있는데, 사실 HTTP/1.1에선 이 기능이 디폴트이기 때문에 굳이 헤더로 명시하지 않아도 기본적으로 지속 연결을 사용합니다.
물론, 서버 자원이 무한대가 아니므로 연결을 무한정 유지하는 것은 아니고 timeout을 설정하여 연결된 소켓에 I/O 요청이 마지막에 종료된 시점으로부터 설정한 timeout 시간 동안 연결을 유지합니다. 물론 설정한 timeout 이내에 또 다른 요청이 들어오면 계속해서 연결을 유지합니다.
이를 그림으로 나타내면 아래와 같습니다:
만약 서버에서 연결을 종료하고자 한다면 아래와 같이 Connection: close 응답 헤더를 명시해야 합니다:
HTTP/1.1 200 OK
Connection: close파이프라이닝
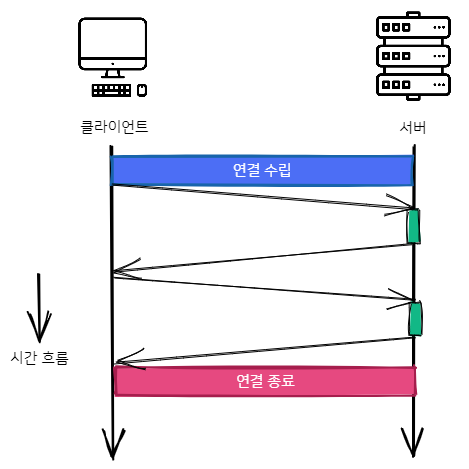
기본적으로 HTTP 요청은 순차적으로 전송됩니다. 즉, 이전 요청의 응답을 받은 이후에야 다음번 요청을 보낼 수 있는 것이죠. 이러한 방식은 네트워크 latency로 인해 지연이 크게 발생할 수도 있습니다.
이러한 단점을 극복하기 위해, HTTP/1.1에는 하나의 연결을 통해 앞선 요청의 응답을 기다리지 않고 여러 요청을 순차적으로 보낸 다음 요청 순서대로 응답받는(뒤에 보낸 요청에 대한 응답이 먼저 올 수도 있으니까요!) 파이프라이닝 기술을 도입했습니다:
하지만 실제로 대부분의 모던 브라우저에선 이러한 파이프라이닝 기술을 사용하지 않는데요, 그 이유는
- 이를 제대로 지원하지 않는 프록시 서버가 존재하고,
- 제대로 구현하기 어렵고,
- 앞선 요청을 기다리지 않고 순차적으로 보낼 수 있긴 하지만 여전히 HOL(Head-of-line blocking)문제가 존재하기 때문입니다. 즉, 예를 들어 첫 번째 요청의 응답이 아직 도착하지 않았다면 두 번째 요청의 응답을 내려줄 수 있는 상황임에도 불구하고 첫 번째 요청의 응답이 도착할 때까지 기다려야 하는 문제가 있습니다.
이러한 문제로 인해 HTTP/1.1의 파이프라이닝 기술은 HTTP/2의 멀티플렉싱 기술로 대체되어 실제로는 거의 사용되지 않습니다.
SPDY
HTTP/1.1 까지 존재했던 성능 이슈를 다시 한번 짚어보자면 아래와 같습니다:
- 기본적으로 앞선 요청에 대한 응답이 도착하기 전엔 다음 요청을 보낼 수 없는 HOL 문제가 존재했습니다. 혹여 파이프라이닝을 도입한다고 하더라도, 이전 요청의 응답이 도착하기 전에 다음 요청을 보낼 수 있게 되지만 응답을 요청 순서에 따라 받아야 하므로 여전히 HOL 문제가 존재합니다.
- 응답을 보낸 뒤 연결을 끊기 때문에, 여러 요청을 보내는 경우 매번 TCP handshake, (필요하다면) TLS negotiation, (필요하다면) DNS lookup 과정을 거쳐야 해서 오버헤드가 발생합니다. 또한 TCP를 통해 데이터를 전송할 때, 처음에는 데이터를 적게 보내고 점점 보내는 양을 늘려가는 slow start 방식을 사용하기 때문에 이에 따른 성능 저하도 발생합니다.
- 이러한 한계점을 보완하기 위해 Keep-Alive 기능을 사용하기도 하고, 또 브라우저에서 한 도메인 당 여러 개의 연결을 생성하여 요청을 병렬로 처리함으로써 HOL 문제 등을 어느 정도 해소하긴 하지만 근본적인 해결책이라고 할 순 없습니다.
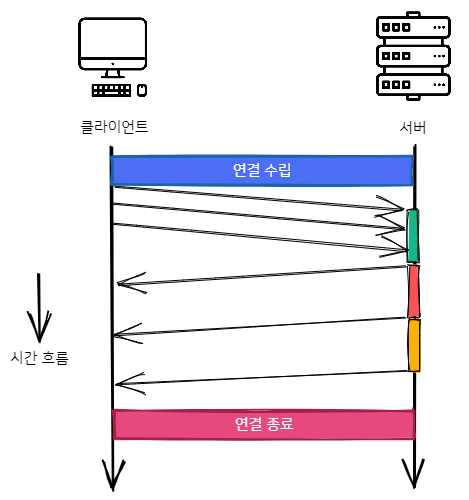
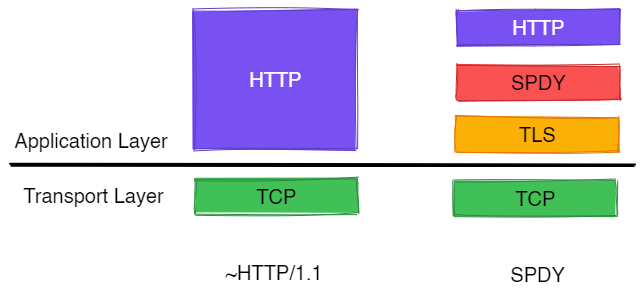
이러한 문제를 근본적으로 해결하기 위해, 2009년 구글에서 SPDY(“스피디”라고 읽는 듯 합니다)라는 실험용 프로토콜을 개발하였습니다. SPDY는 HTTP와는 완전 별개의 프로토콜이 아니라 TLS 위에서 동작하는 프로토콜로, HTTP 요청을 보내면 이를 SPDY 요청으로 변환하여 서버에 날리고, 응답을 다시 HTTP로 변환하는 방식으로 동작합니다.
실제 여러 사이트를 대상으로 SPDY를 실험한 결과, 페이지 로딩 속도가 최대 55% 향상되는 성과를 보였다고 합니다. 이후 2010년 가을부터 구글 크롬에서 SPDY를 지원하기 시작했고, 파이어폭스와 오페라는 2012년부터 지원하기 시작했습니다.
SPDY가 HTTP/1.1 까지 존재했던 한계점을 극복하기 위해 도입한 기술들을 간략히 소개하자면 다음과 같습니다:
- Multiplexed streams: 하나의 TCP 연결을 통해 여러 요청·응답을 독립적인 스트림으로 묶어 처리합니다. 또한, 한 스트림이 진행 중이더라도 다른 스트림이 끼어드는(interleaving) 것이 가능합니다.
- Request prioritization: 각 스트림의 우선순위를 설정하여 우선순위가 낮은 데이터를 전송하는 와중에 우선순위가 높은 데이터가 끼어들어서 더 빨리 전달될 수 있도록 합니다.
- Binary protocol: 프레임을 텍스트가 아닌 바이너리로 구성하여 파싱을 더욱 빠르게 하고 오류 발생 가능성을 낮춥니다.
- Header compression: 헤더 압축을 통해 요청 데이터의 크기를 더욱 작게 할 수 있게 됩니다.
- Server push: 서버 푸시를 통해 클라이언트가 요청하지 않은 컨텐츠도 서버가 미리 빠르게 전송하여 RTT를 줄일 수 있습니다. 예를 들어, 클라이언트가 서버에
index.html파일을 요청한 경우 서버에서 CSS 파일도 같이 내려주어 클라이언트가 서버로 보내는 CSS 요청만큼의 시간을 절약할 수 있습니다.
HTTP/2
SPDY를 통해 HTTP/1.1에서 존재했던 한계점을 극복할 수 있다는 사실을 확인한 HTTP WG는 약 SPDY를 기반으로 다음 버전의 HTTP를 만드는 작업에 착수하였으며, 약 2년가량의 작업 끝에 2015년 5월에 RFC 7540 문서로 공식 발표되었습니다.
HTTP/2의 주목적은 앞서 SPDY에서도 살펴봤듯이 멀티플렉싱 방식을 사용하여 요청·응답을 처리하고, HTTP 헤더 압축을 통해 헤더에 의한 오버헤드를 줄이는 등의 기법을 통해 HTTP/1.1까지 존재했던 HOL과 같은 문제들을 근본적으로 해결하면서 latency를 줄이는 것입니다. 앞서 SPDY 섹션에서 간략히 소개했던 기능들을 자세히 살펴보겠습니다.
이진 프레이밍 레이어 (Binary Framing Layer)
HTTP/1.1까지는 각 요청·응답이 메시지라는 단위로 구성되어 있었습니다. 그리고 각 메시지에는 상태 라인(status line), 헤더 및 페이로드로 구성되어 요청과 응답에 필요한 정보가 저장되고, 이러한 요청·응답을 ASCII로 인코딩하여 표현하였습니다.
하지만 HTTP/2에선 이진 프레이밍 레이어(Binary Framing Layer)라는 새로운 레이어를 통해 메시지를 이진 형식으로 캡슐화하여 데이터를 주고받습니다. HTTP/2에는 메시지 이외에 스트림과 프레임이라는 단위가 추가되었는데, 각각의 구조를 설명하자면 다음과 같습니다:
- 스트림(Stream): 클라이언트와 서버 사이에 맺어진 연결을 통해 양방향으로 주고받는 메시지의 “흐름”입니다. 한 연결 내의 가상 채널이라고 할 수 있습니다.
- 메시지(Message): HTTP/1.1에서와 마찬가지로 요청·응답의 단위이며, 다수의 프레임으로 구성됩니다.
- 프레임(Frame): HTTP/2 통신의 가장 작은 단위로, HTTP 헤더, 페이로드와 같은 데이터가 저장됩니다.
즉, HTTP/2에선 여러 개의 프레임이 모여 메시지가 되고, 여러 개의 메시지가 모여 스트림이 되는 구조입니다:
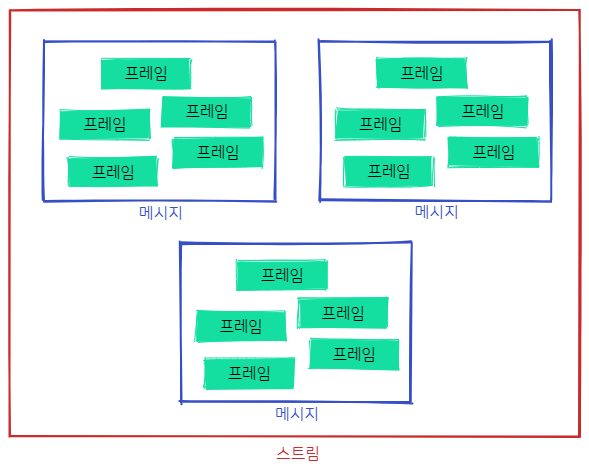
HTTP/1.1까지는 요청·응답이 메시지라는 단위로 완벽히 구분되어 있었으나, HTTP/2에선 스트림이라는 단위를 통해 요청·응답이 하나의 단위로 묶일 수 있는 구조가 되었습니다.
각 스트림은 31비트 unsigned 타입의 정수를 사용해서 식별하며, 클라이언트가 시작한(initiate) 스트림은 홀수 번호를 사용하고 서버가 시작한 스트림은 짝수 번호를 사용합니다(또한, 0번 스트림은 연결 제어 메시지를 전송할 때 사용됩니다). 또한 HTTP/1.1에서 연결을 재사용할 수 있었던 것과는 달리, HTTP/2의 스트림은 재사용되지 않습니다.
요청·응답을 보낼 때 이러한 스트림 번호를 각 요청·응답 프레임에 매핑하는데, 클라이언트는 응답 스트림의 번호를 통해 어떤 요청에 대한 응답인지 구분합니다:
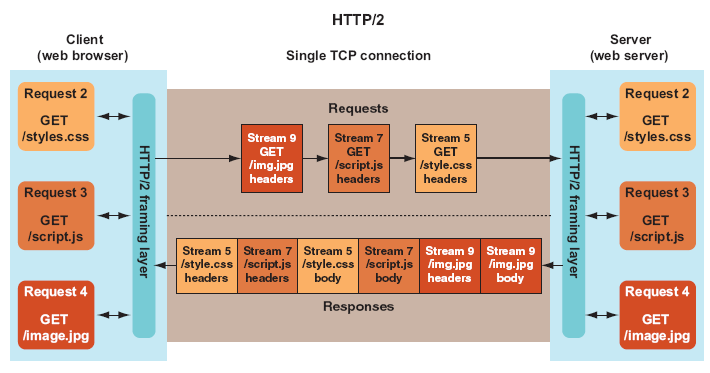
위 그림에선 하나의 TCP 연결에 여러 개의 스트림(5, 7, 9번)이 존재하고 있습니다. 또, 프레이밍 레이어를 통해 각 요청 및 응답을 바이너리 프레임으로 변환하고 있음을 알 수 있는데, 각 요청 메시지들은 하나의 헤더 프레임으로만 구성되어 있고, 각 응답 메시지들은 두 개의 프레임(헤더, 바디)으로 구성되어있음을 알 수 있습니다. 그리고 각각의 프레임에 스트림 번호를 매겨 서로 연관된 요청 프레임과 응답 프레임을 구분하고 있음을 알 수 있습니다.

이러한 스트림 구조 덕분에 서버에서 만들어지는 응답 프레임들이 요청 순서에 상관없이 응답이 만들어진 순서대로 클라이언트에게 전달될 수 있게 되었습니다. 즉, 하나의 TCP 연결을 통해 여러 요청과 응답이 비동기 방식으로 이뤄지는 “멀티플렉싱”이 사용되는 것인데, 이를 통해 HTTP/1.1까지 존재했던 HOL 문제를 해결할 수 있게 되었습니다.
멀티플렉싱
HTTP/1.1에선 하나의 TCP 연결에서 한순간에 최대 하나의 응답만을 보낼 수 있었습니다. 이에 따라 어떤 한 응답이 지연되면 이후의 응답이 모두 지연되는 HOL 문제가 발생했었습니다. 물론 이러한 한계를 극복하기 위해 여러 개의 연결을 생성하여 병렬적으로 처리하려고 했으나, 이 방식 또한 연결을 생성할 때마다 TCP handshake, (필요하다면) TLS negotiation을 거쳐야 하고 또 TCP slow start로 인한 성능 저하 문제가 여전히 존재했었습니다.
하지만 HTTP/2에선 스트림이 가진 유연한 구조 덕분에 응답 프레임을 요청 순서와 관계없이 클라이언트에게 전달할 수 있게 되었습니다. 즉, 하나의 TCP 연결 내에서 다수의 클라이언트 요청과 서버 응답이 비동기 방식으로 이뤄지는 멀티플렉싱(multiplexing) 방식이 도입된 것이죠.
앞서 이진 프레이밍 레이어를 알아볼 때 살펴봤듯이, 멀티플렉싱은 하나의 HTTP 메시지를 여러 프레임으로 나눠 서로 교차(interleave)하여 전송하고 이를 다시 하나로 합치는 방식으로 동작합니다:
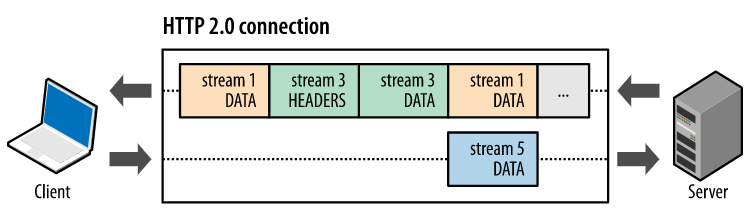
위와 같은 방식을 통해, 여러 개의 TCP 연결을 생성할 필요가 없어졌고, 또한 처리가 오래 걸리는 응답으로 인한 병목 현상을 제거함으로써 자연스레 HOL 문제를 해결하였습니다.
스트림 우선순위
HTTP/1.1 까지는 하나의 요청·응답으로 동작했기 때문에 프로토콜 레벨에서 우선순위를 결정하는 것이 아니라 클라이언트에서 어떤 순서로 요청을 할 것인가를 결정했었습니다. 이를테면 HTML, CSS, 자바스크립트와 같은 크리티컬한(초기 렌더링에 꼭 필요한) 자원을 먼저 요청하고, 상대적으로 덜 중요한 이미지 등을 나중에 요청하는 방식이었습니다.
하지만 HTTP/2에선 멀티플렉싱 방식을 통해 여러 프레임을 서로 교차시켜 전송할 수 있다 보니, 이미지와 같이 상대적으로 덜 중요한 자원이 대역폭을 소모함으로 인해 페이지 로딩이 느려질 수 있습니다. 따라서 각 스트림의 우선순위를 설정하여 우선순위가 높은 중요한 자원이 더 빨리 전달되게 할 수 있습니다.
HTTP/2에서 스트림의 우선순위를 정할 때, 클라이언트는 1~256 사이의 가중치와 다른 스트림에 대한 의존성을 명시하여 우선순위 트리를 만듭니다. 그러면 서버는 이 트리를 보고 스트림의 우선순위에 따라 CPU, 메모리 같은 자원을 할당하고, 응답을 보낼 때 우선순위가 높은 스트림이 최적으로 전달되도록 대역폭을 할당합니다.
우선순위 트리는 부모 스트림에서 자식 스트림을 가리키는 방식으로 의존 관계를 나타내고, 각 스트림에 가중치를 할당하여 같은 부모를 가지는 sibling 스트림에 대해 자원을 어느 비율로 할당할지 결정하게 됩니다. 아래 그림을 통해 우선순위 트리를 어떻게 해석하는지 살펴보겠습니다:
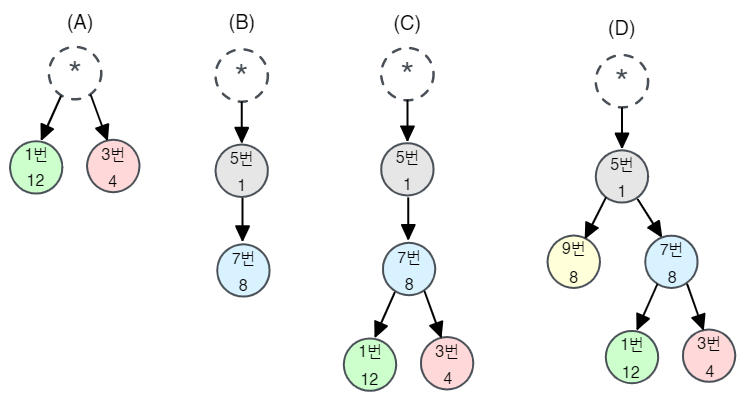
(A)
스트림 1번과 3번 모두 암묵적인 “루트”를 부모로 하고 있습니다. 이때 스트림 1번의 가중치는 12이고 3번의 가중치는 4이므로, 각 스트림의 가중치에 모든 sibling 스트림의 가중치를 합한 16을 나눈 만큼 자원을 할당합니다. 따라서 스트림 1번은 전체 자원의 75%(12/16), 스트림 3번은 25%(4/16)을 가져가게 됩니다.
(B)
스트림 5번이 7번의 부모 스트림이므로, 스트림 5번이 먼저 모든 자원을 할당받고, 그다음으로 스트림 7번이 모든 자원을 할당받습니다. 이처럼 부모·자식 간에는 가중치에 따라 자원을 할당하지 않습니다.
(C)
스트림 5번이 먼저 모든 자원을 할당받고, 그다음으로 스트림 7번이 모든 자원을 할당받고, 마지막으로 스트림 1번은 모든 자원의 75%만큼, 스트림 3번은 모든 자원의 25%만큼 할당받게 됩니다.
(D)
스트림 5번이 먼저 모든 자원을 할당받고, 그다음으로 스트림 7번과 9번이 동일하게 50%씩 할당받고, 마지막으로 스트림 1번이 75%만큼, 3번이 25%만큼 할당받게 됩니다.
⚠️ 이때, 서버가 항상 우선순위 트리에 따라 스트림을 특정 순서로 처리한다는 보장은 없습니다. 만약 우선순위를 무조건 준수한다고 하면 우선순위가 높은 응답의 처리가 지연되는 경우, 우선순위가 낮은 응답은 보낼 준비가 되었다고 해도 전송할 수 없을 테니까요!
서버 푸시
HTTP/2에선 클라이언트의 요청 없이도 서버에서 응답을 알아서 보낼 수 있는 서버 푸시(Server push) 기능이 추가되었습니다. 클라이언트가 특정 컨텐츠, 예를 들어 index.html을 요청하면 서버는 이후 추가될 요청을 예상하고 클라이언트가 요청하지 않은 app.css, script.js과 같은 컨텐츠도 함께 내려주게 됩니다. 이렇게 하면 굳이 요청을 보내지 않아도 필요한 리소스를 응답받을 수 있어 보내지 않은 요청만큼의 자원과 시간을 절약하는 효과를 얻을 수 있습니다.

헤더 압축
HTTP/1.1에선 HTTP 헤더가 일반 텍스트의 형태로 전송되었습니다. 이로 인해 적게는 수백 바이트에서 많게는 수 킬로바이트의 오버헤드가 발생했고, 또 Accept, Content-Type과 같이 자주 사용되는 헤더들을 매 요청마다 중복으로 보내야하는 문제가 있었습니다.
이러한 오버헤드를 줄이고자 HTTP/2에선 HPACK이라는 압축 기법을 통해 헤더를 압축하는데, 이때 아래의 기법을 사용합니다:
- Huffman code를 사용해서 각각의
name: value헤더쌍을 압축합니다. - 미리 정의된 정적 테이블을 사용합니다.
- 한 연결 내에서 사용된 헤더를 클라이언트와 서버가 서로 공유하는 동적 테이블에 저장합니다.
우선 name: value 헤더쌍이 동적 테이블에 있는지 살펴보고, 만약 동적 테이블에 존재한다면 이 헤더쌍을 동적 테이블의 엔트리를 가리키는 포인터로 바꿉니다. 만약 헤더쌍 전체를 찾을 수 없다면 정적 테이블에 헤더의 이름(name)이 존재하는지 살펴보고, 존재한다면 마찬가지로 해당 헤더 이름을 포인터로 바꿉니다.

레퍼런스
- HTTP/2 in Action | Manning Publications
- RFC 2616 - Hypertext Transfer Protocol — HTTP/1.1
- RFC 7540 - Hypertext Transfer Protocol Version 2 (HTTP/2)
- Evolution of HTTP - HTTP | MDN
- Connection management in HTTP/1.x - HTTP | MDN
- SPDY는 무엇인가? | Naver D2
- 웹에 날개를 달아주는 웹 성능 최적화 기법 | 루비페이퍼
- Introduction to HTTP/2 | web.dev