히든 클래스와 인라인 캐싱
카테고리: JavaScriptMay 23, 2022
이 포스트에선 구글 V8 엔진의 TurboFan과 같이, 대부분의 자바스크립트 엔진에서 성능 최적화를 위해 사용하는 히든 클래스와 인라인 캐싱 기법에 대해 간단히 알아보겠습니다.
히든 클래스
자바스크립트 엔진이 객체를 표현하는 방법
우선 자바스크립트 엔진이 어떻게 자바스크립트 객체를 내부적으로 구현하고, 또 객체 프로퍼티 접근 속도를 향상하기 위해 어떠한 기법을 사용하는지 살펴봅시다.
ECMAScript 스펙에 따르면, 자바스크립트 객체는 key-value 쌍으로 이루어진 프로퍼티들의 집합입니다. 이때 key의 타입에는 문자열 혹은 Symbol이 가능하며 key는 property attribute 라는 value에 대응되는데 이를 살펴보면 다음과 같습니다:
[[Value]]: 프로퍼티의 값을 의미합니다. 프로퍼티의 값으로는 자바스크립트의 모든 값(숫자, 문자열, 객체, 함수 등)을 사용할 수 있습니다.[[Writable]]:=연산자를 이용하여 값을 할당할 수 있는지를 나타냅니다.[[Enumerable]]:for...in과 같은 연산을 통해 “열거(enumerate)“할 수 있는지를 나타냅니다.[[Configurable]]:delete연산자로 해당 속성을 지울 수 있는지, 그리고defineProperty()로 다른 프로퍼티 속성을 변경할 수 있는지를 나타냅니다.
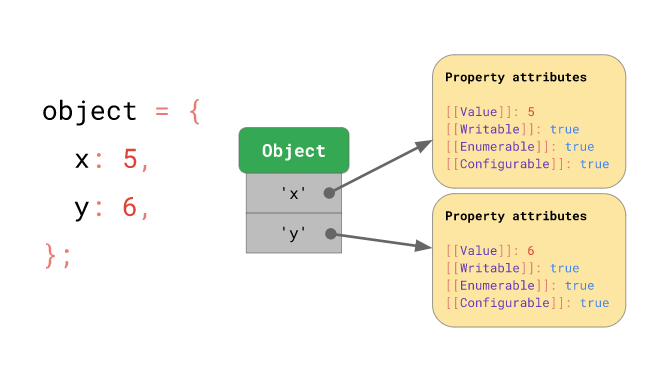
예를 들어, 객체
const object = {
x: 5,
y: 6
};를 그림으로 표현하면 아래와 같습니다:
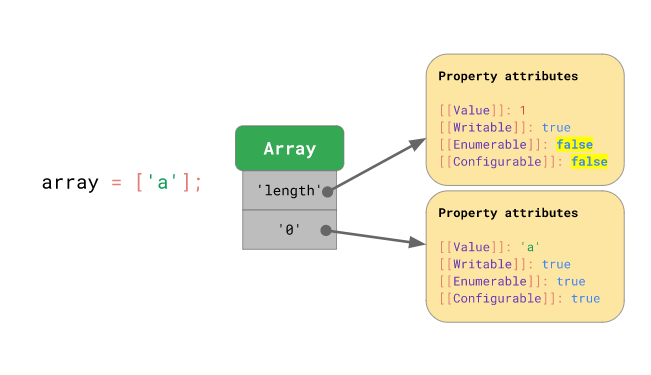
자바스크립트에선 배열도 객체인데, 일반적인 객체와의 차이점이라면 현재 배열에 담긴 프로퍼티의 개수를 나타내는 length 라는 특별한 프로퍼티가 존재한다는 점과 배열의 각 key는 0부터 232 - 1 까지의 정수값이라는 점입니다 (이러한 key를 배열의 인덱스라고 합니다):
const arr = ['a', 'b'];
arr.length; // 2
// 위 배열을 일반적인 객체의 형태로 나타내면 아래와 같습니다.
// (물론 실제 배열과 100% 똑같지는 않습니다)
const arrLike = {
0: 'a',
1: 'b',
};
Object.defineProperty(arrLike, 'length', {
value: 2,
writable: true
});
// 일반 객체처럼, 배열에도 문자열을 key로 사용할 수는 있습니다만,
// 일반적인 경우는 아닙니다.
arr.hello = 'world';
console.log(arr); // [ 'a', 'b', hello: 'world' ]배열을 내부적으로 표현하는 방식도 객체를 표현하는 방식과 매우 흡사합니다:
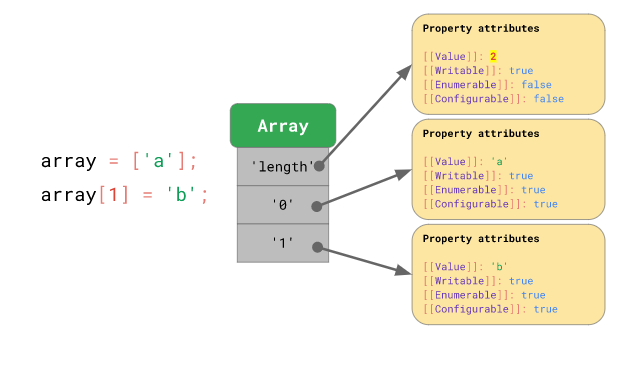
배열에 요소를 추가하는 경우 자바스크립트 엔진이 알아서 배열의 length 프로퍼티 값을 증가시킵니다:
프로퍼티 접근 최적화 하기
자바스크립트를 사용하다 보면 가장 많이 하는 동작 중 하나가 바로 객체 프로퍼티 접근 연산입니다. 따라서 객체 프로퍼티에 접근하는 연산을 최적화할 필요가 있는데, 자바스크립트 엔진이 어떻게 최적화를 하는지 살펴보겠습니다.
같은 프로퍼티 key를 가지는 객체들은 같은 “모양”을 가진다고 할 수 있습니다:
// 아래의 객체들은 모두 같은 "모양"을 가집니다
const obj1 = { x: 1, y : 2 };
const obj2 = { x: 10, y : 20 };
const obj3 = { x: 5, y : 6 };자바스크립트 엔진은 이러한 객체의 “모양”을 토대로 객체 프로퍼티 접근을 최적화합니다. 우선, x 와 y 프로퍼티를 가진 객체가 있다고 해봅시다. 이 객체의 y 프로퍼티에 접근하는 경우(e.g. obj.y), 자바스크립트 엔진은 우선 해당 객체의 y 프로퍼티에 대한 프로퍼티 속성 을 살펴본 다음 최종적으로 [[Value]] 속성의 값을 반환합니다:
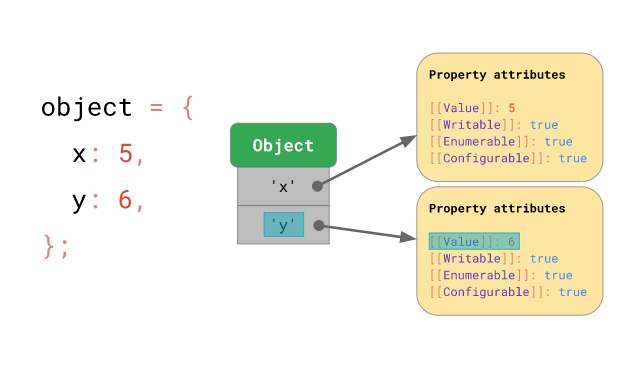
그럼 객체의 프로퍼티 속성 은 메모리 어디에다가 저장해야 할까요? 위 그림처럼 객체의 일부로서 저장한다면, 같은 “모양”을 가진 객체들이 많은 경우 동일한 “모양”을 가진 객체들마다 따로 프로퍼티의 이름과 프로퍼티 속성을 저장하게 되어 메모리가 낭비됩니다. 동일한 프로퍼티 이름이 중복으로 저장되고, 동일한 프로퍼티 속성값들 또한 중복으로 저장되기 때문이죠 ([[Value]] 의 값은 다를지언정 [[Enumerable]] 과 같은 속성값들은 일반적으로 동일한 확률이 높으니까요!).
따라서 이를 최적화하기 위해 자바스크립트 엔진은 객체의 “모양”을 따로 저장하고, 이 “모양”에다가 객체의 모든 프로퍼티 이름과 그에 대한 속성 정보를 저장합니다. 단, 속성 정보를 저장할 때 [[Value]] 는 “모양”이 아니라 객체에 저장되고, “모양”에는 객체 내에서의 해당 값의 인덱스(오프셋)를 저장합니다. 아래 그림을 보시면 이해가 되실겁니다:
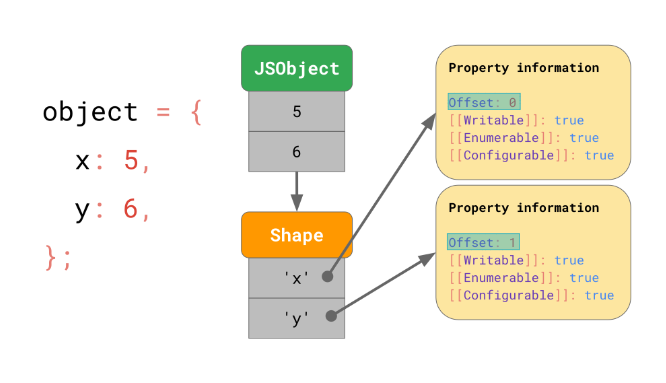
이를 종합해보면 각 객체들은 프로퍼티의 값만 저장하고, 해당 객체의 “모양” 인스턴스를 가리킵니다. 그리고 “모양” 인스턴스에는 프로퍼티의 이름과 해당 이름에 대한 프로퍼티 속성 정보 및 실제 객체에서 해당 프로퍼티가 몇 번째 인덱스(오프셋)인지를 나타냅니다. 그리고 이 인덱스를 통해 자바스크립트 엔진이 실제 객체에서 프로퍼티의 값을 어떻게 찾을지 알 수 있는 것이죠:
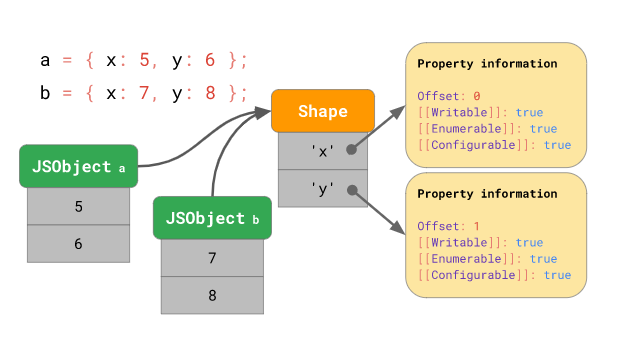
이러한 방식을 사용하면 똑같은 “모양”을 가진 여러 객체들이 존재하는 경우 각 객체들의 프로퍼티 이름과 그에 대한 프로퍼티 속성 정보를 한 번만 저장하면 된다는 이점이 있습니다.
여태껏 “모양”이라는 단어를 계속해서 사용해왔는데, 사실 자바스크립트 엔진마다 이를 부르는 방식이 조금씩 다릅니다:
- 학술적으론 Hidden Class라는 말을 사용합니다 (물론 자바스크립트의 클래스와는 아무런 관련이 없습니다).
- V8 엔진에선 Map이라고 부릅니다 (물론 자바스크립트의
Map자료구조 혹은 배열의.map()메서드와는 아무런 관련이 없습니다). - Chakra 엔진에선 Type이라고 부릅니다.
- JavaScriptCore 엔진에선 Structure라고 부릅니다.
- SpiderMonkey 엔진에선 Shape이라고 부릅니다.
사실 위와 같은 내용과 관련해서 “히든 클래스”라는 말을 제일 많이 접해보셨을 겁니다. 하지만 히든 클래스 대신 “모양”이라는 단어를 계속해서 사용하도록 하겠습니다.
Transition 체인과 Transition 트리
자바스크립트는 동적 타입 언어이므로 런타임에 객체 프로퍼티를 추가(혹은 제거)할 수도 있습니다. 이러면 객체의 모양이 바뀔 텐데 엔진은 이를 어떻게 처리할까요?
const o = {};
o.x = 5;
o.y = 6;이 경우, 모양 인스턴스 는 transition 체인 을 형성합니다:
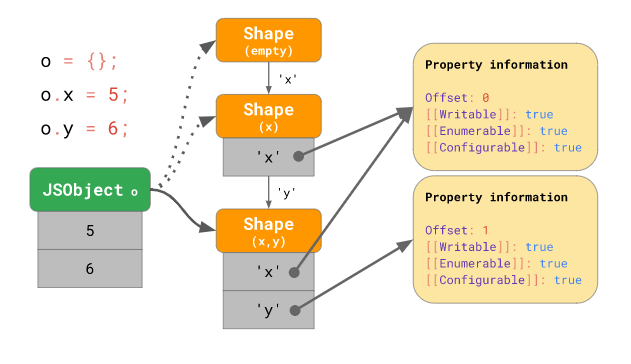
처음엔 아무것도 없는 빈 모양({})에서 시작했다가, o.x = 5; 구문에 의해 x 프로퍼티가 추가되어 엔진은 기존의 모양을 새로운 모양으로 “전이(transition)” 합니다. 그리고 o.y = 6; 구문에 의해 y 프로퍼티가 추가되어 한 번 더 다른 모양으로 “전이”하게 됩니다. 이때 프로퍼티가 추가되는 순서가 중요하다는 점을 기억해주세요. 예를 들어 x 먼저 추가하고 y 를 추가하면 최종적으로 { x: 0, y: 0 } 과 같은 모양이 되지만, 반대로 y 먼저 추가하고 x 를 추가하면 최종적으로 { y: 0, x: 0 }의 형태가 되어 { x: 0, y: 0 } 과는 완전히 다른 모양이 됩니다.
하지만 실제로는 위 그림의 Shape (x, y) 와 같이 각 모양 인스턴스마다 모든 프로퍼티의 정보를 저장하는 것이 아니라, 아래 그림처럼 해당 모양 인스턴스 가 생성될 때 추가된 프로퍼티에 관한 정보만을 저장합니다:
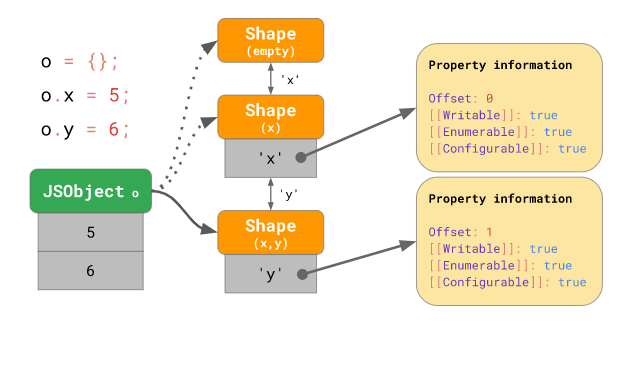
그리고 (마치 프로토타입 체인처럼) 특정 모양 인스턴스에 존재하지 않는 프로퍼티를 찾기 위해, 다음 모양 인스턴스 에서 이전 모양 인스턴스 를 가리키는 포인터가 추가됩니다 (기존의 단방향 포인터에서 양방향 포인터가 되는 것이죠). 예를 들어 o.x 와 같이 어떤 객체의 x 프로퍼티에 접근하는 경우, 엔진은 x 프로퍼티를 가지는 모양을 찾을 때까지 transition 체인을 거슬러 올라갑니다.
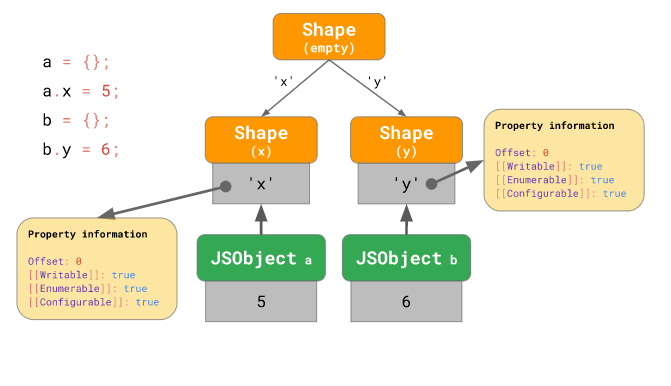
하지만 아래의 경우와 같이 transition 체인을 생성할 수 없는 경우가 있습니다:
const a = {};
a.x = 5;
const b = {};
b.y = 6;위 코드처럼 처음에는 같은 모양({}) 이었다가 서로 완전히 다른 모양({ x: 5 } 와 { y: 6 })으로 “분기”한 경우, 기존의 transition 체인을 형성할 수 없습니다. 대신 이 경우엔 transition 트리 를 형성합니다:
하지만 그렇다고 항상 빈 모양({})에서 시작하는 것은 아닙니다. 다음 예시를 살펴봅시다:
const a = {};
a.x = 5;
const b = { x: 6 };a 객체의 경우, 우리가 이전에 본 것처럼 빈 모양({})에서 시작하여 { x: ... } 모양으로 “전이”합니다. 하지만 b 객체의 경우 빈 모양에서 시작하는 것이 아니라 처음부터 { x: ...} 모양에서 시작합니다:
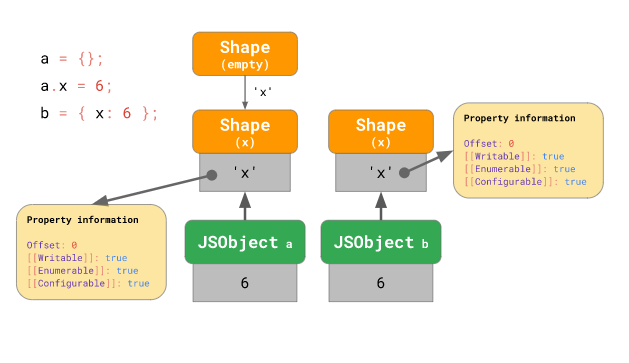
최소한 V8 엔진과 SpiderMonkey 엔진에선 객체 리터럴에 대해 이런 식으로 최적화하여 transition 체인의 길이를 되도록 짧게 유지합니다.
앞서 객체의 프로퍼티에 접근할 때(e.g. obj.x) 실제 객체가 가리키는 모양 인스턴스 에서 시작하여 해당 프로퍼티를 찾을 때까지 체인을 따라 이동한다고 했는데, 사실 이 방식은 시간 복잡도가 O(n) 만큼 걸리는 연산이라서 transition 체인이 긴 경우 비효율적일 수 있습니다. 따라서 엔진은 ShapeTable 이라는 것을 두어 객체 접근 연산을 최적화 하는데요, ShapeTable의 각 엔트리는 프로퍼티의 key와 해당 프로퍼티를 가지고 있는 모양 인스턴스 를 매핑합니다:
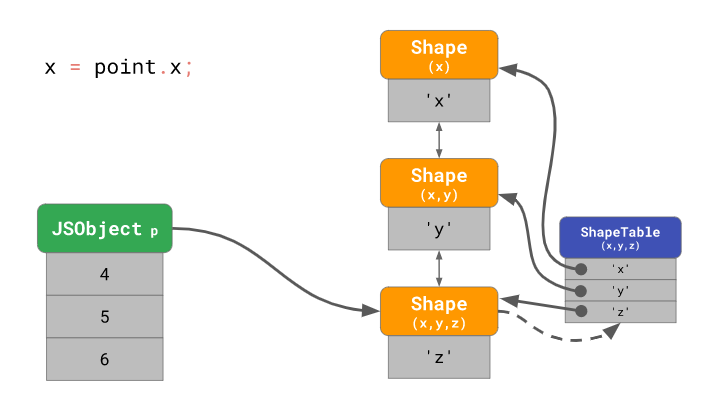
또한, 모양 인스턴스 를 사용하면 인라인 캐시(Inline Cache)라는 또 다른 최적화 기법을 도입할 수 있습니다. 이를 살펴봅시다.
인라인 캐시
사실, 앞서 살펴본 모양 인스턴스 를 사용하는 주된 이유는 인라인 캐시(Inline Cache, IC)라는 최적화 기법을 사용하기 위함입니다.
인라인 캐시는 객체의 프로퍼티를 어디서 찾아야 하는지에 대한 정보를 캐싱함으로써 자바스크립트의 성능을 최적화하는 주된 요소인데요, 예를 들어 다음 코드와 같이 인자로 넘겨받은 객체의 프로퍼티에 접근하는 함수를 살펴봅시다:
function getX(o) {
return o.x;
}이 코드를 실행하면 엔진은 다음과 같은 바이트 코드를 생성합니다:
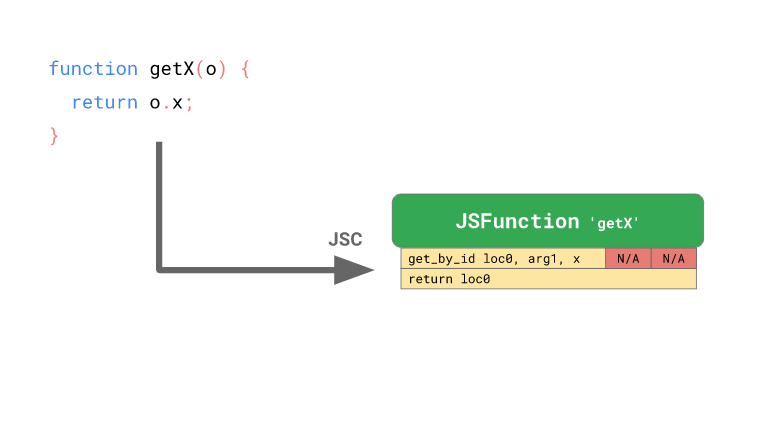
위 그림에서 첫 번째 바이트 코드 get_by_id 는 첫 번째 인자(arg1)로 부터 프로퍼티 x 를 로드하여 그 결과값을 loc0 레지스터에 저장합니다. 그러고 나서 두 번째 바이트 코드 return loc0 는 loc0 에 저장해두었던 값을 리턴하지요. 이때 엔진이 get_by_id 바이트 코드에 초기화되지 않은 두 개의 슬롯을 할당한 것을 주목해주세요.
그리고 { x: 'a' } 객체를 인자로 해서 getX() 함수를 실행했다고 해봅시다. 앞서 살펴본 것처럼 이 객체는 x 프로퍼티를 가진 모양 인스턴스 를 가리킬 것이고, 해당 모양 인스턴스 에는 프로퍼티의 오프셋과 프로퍼티 속성 정보가 저장될 것입니다:
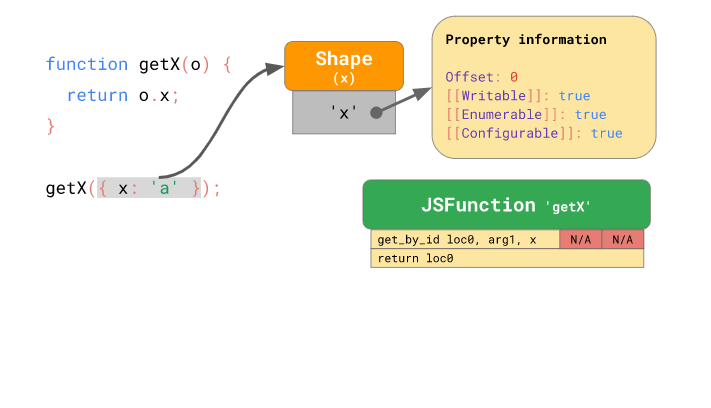
함수 getX() 를 처음 실행한 경우, get_by_id 바이트 코드는 모양 인스턴스 로 부터 x 프로퍼티에 관한 정보를 찾아 x 프로퍼티의 오프셋이 0 이라는 사실을 알아내게 됩니다. 이때, 단순히 이러한 정보를 찾아내는 것에 그치지 않고 엔진은 해당 정보를 찾는 데 사용된 모양 인스턴스 와 프로퍼티의 오프셋을 get_by_id 바이트 코드에 저장합니다:
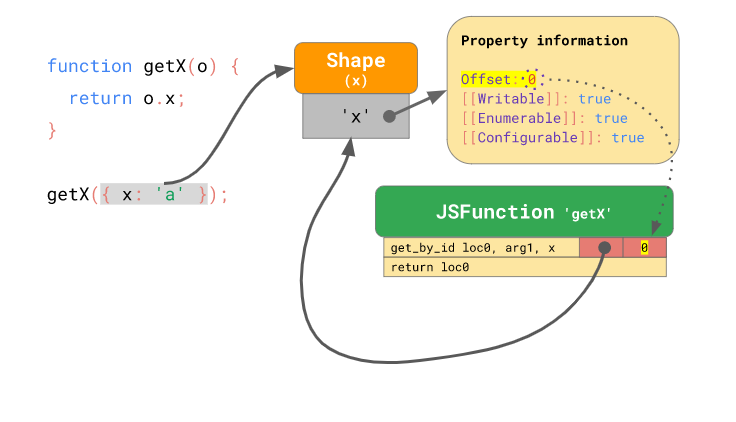
이렇게 하면 이후에 getX() 함수를 실행했을 때, 바이트 코드의 인라인 캐시에 저장된 모양 인스턴스 를 비교한 후 만약 모양 인스턴스 가 같다면(즉, 객체가 같은 “모양”이라면) 앞서 수행했던 작업을 처음부터 일일이 수행할 필요 없이 캐시 된 오프셋을 통해 객체의 프로퍼티에 접근하면 됩니다. 즉, 엔진이 IC에 저장된 것과 같은 모양 인스턴스 임을 확인한 경우 굳이 모양 인스턴스 의 프로퍼티 속성 정보를 찾아서 오프셋을 알아내는 과정을 거칠 필요 없이 IC에 저장된 오프셋을 통해 실제 객체에서 값을 찾으면 된다는 것입니다:
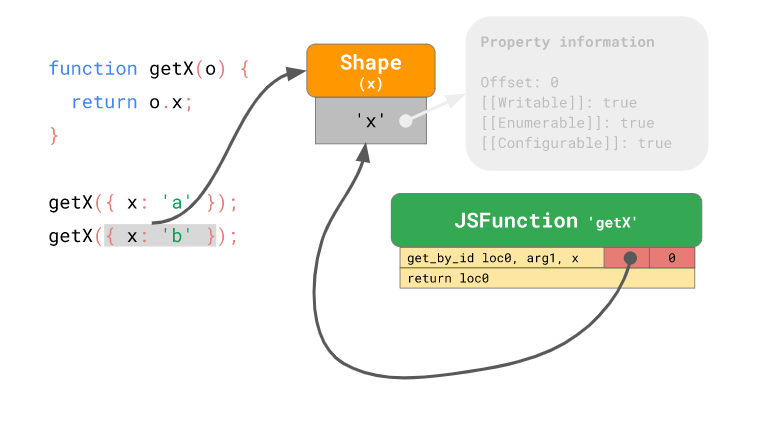
이렇게 인라인 캐시를 통해 모양 인스턴스 와 오프셋을 캐싱함으로써 정보를 찾는 과정을 생략하여 프로퍼티 접근 속도를 크게 향상시킬 수 있습니다.
배열을 효율적으로 저장하기
일반적으로 배열은 “인덱스”를 key로 하여 프로퍼티를 저장하는데, 인덱스를 key 값으로 갖는 프로퍼티(배열 요소)의 프로퍼티 속성은 기본적으로 writable: true, enumerable: true, configurable: true 라는 사실을 이용하여 배열을 효율적으로 저장할 수 있습니다. 각 배열 요소마다 이와 같은 동일한 프로퍼티 속성을 저장한다면 메모리가 크게 낭비되는 것이니 이를 최적화하는 것이죠!
// 배열의 요소는 기본적으로 writable, enumerable, configurable 입니다.
const arr = [1, 2, 3];
console.log(Object.getOwnPropertyDescriptor(arr, '0')); // { value: 1, writable: true, enumerable: true, configurable: true }예를 들어 아래 배열을 예로 들어보면:
const a = ['#jsconfeu'];엔진은 먼저 배열 객체에 length 프로퍼티 값을 저장하고, 배열 객체가 length 프로퍼티에 관한 프로퍼티 속성과 오프셋을 저장하는 모양 인스턴스 를 가리키도록 합니다:
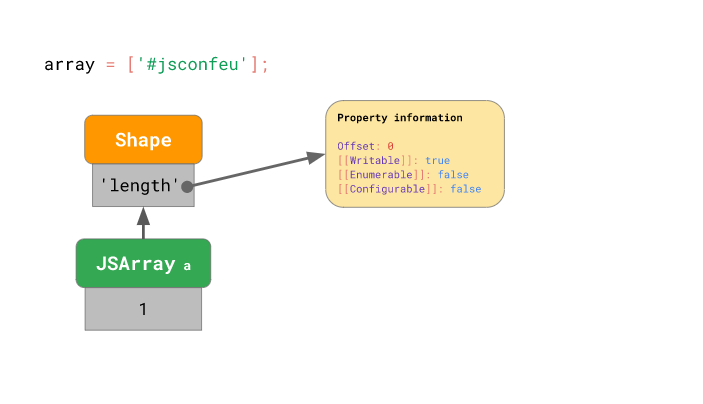
그리고 인덱스를 key로 갖는 프로퍼티들은 배열의 다른 프로퍼티와 분리하여 저장합니다 (배열도 객체이므로 배열 a 에 a.x = 1 과 같이 문자열을 key로 갖는 프로퍼티를 추가할 수 있음을 기억해주세요!):
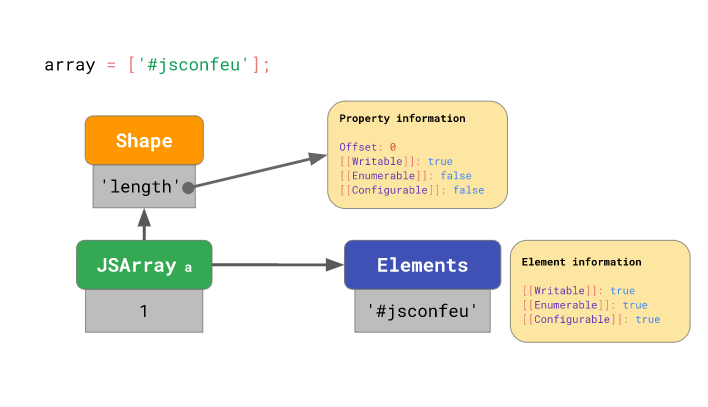
이렇게 배열 요소(인덱스 key를 사용하는 프로퍼티)의 프로퍼티 속성 정보를 각 요소 마다 따로 저장할 필요가 없는 이유는 앞서 말한 것처럼 배열 요소의 프로퍼티 속성 정보는 기본적으로 writable: true, enumerable: true, configurable: true 이기 때문입니다.
하지만 Object.defineProperty 를 이용하여 배열 요소의 프로퍼티 속성 정보를 바꿔버린다면 어떻게 될까요?
// 따라하지 마세요!
const arr = Object.defineProperty(
[],
'0',
{
value: 'NEVER DO THIS PLEASE',
writable: false,
enumerable: false,
configurable: false,
}
);이 경우 엔진은 배열 요소를 저장하는 스토어의 형태를 아래 그림과 같이 딕셔너리 형태로 바꿔 배열의 인덱스를 딕셔너리의 key로 하고, 이 인덱스에 해당하는 배열 요소의 프로퍼티 속성을 가리키도록 합니다:
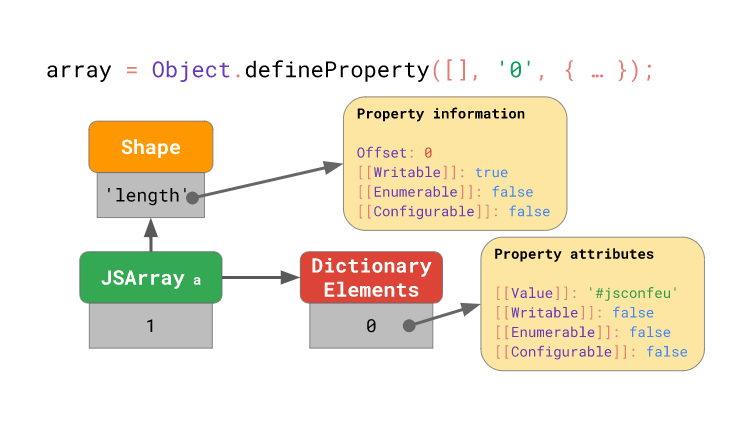
프로퍼티 속성이 기본값이 아닌 배열 요소가 단 하나만 존재해도 엔진은 위와 같이 딕셔너리의 형태로 배열 요소를 저장합니다. 이는 기존의 방식에 비해 비효율적이고 느린 방식이므로 웬만하면 Object.defineProperty 메서드를 이용하여 배열 요소의 프로퍼티 속성을 변경하지 않는 것을 권장합니다!
프로토타입 프로퍼티 접근 최적화
프로토타입 도 우리가 앞서 살펴본 방식과 동일하게 동작합니다. 왜냐하면 자바스크립트의 프로토타입 또한 일반 객체니까요! 아래 예시를 살펴봅시다:
function Bar(x) {
this.x = x;
}
Bar.prototype.getX = function getX() {
return this.x;
};
// 위 프로토타입 기반 코드는 아래의 클래스 기반으로 바꿀 수 있습니다:
class Bar {
constructor(x) {
this.x = x;
}
getX() {
return this.x;
}
}
// 인스턴스화
const foo = new Bar(true);위 코드를 실행하여 foo 인스턴스를 생성하면 내부적으로 아래와 같은 구조가 형성됩니다:
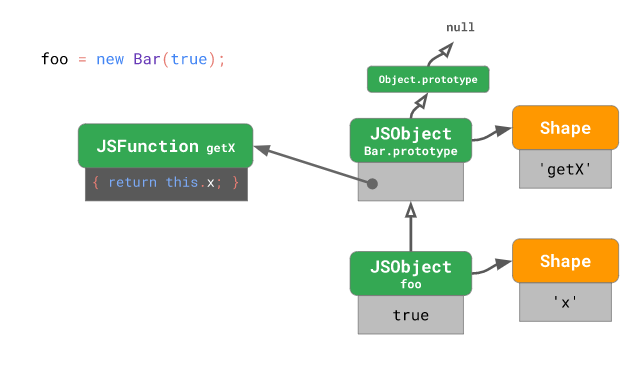
위 상황에서 아래와 같이 또 다른 인스턴스를 생성한 경우는 아래와 같습니다:
const qux = new Bar(false);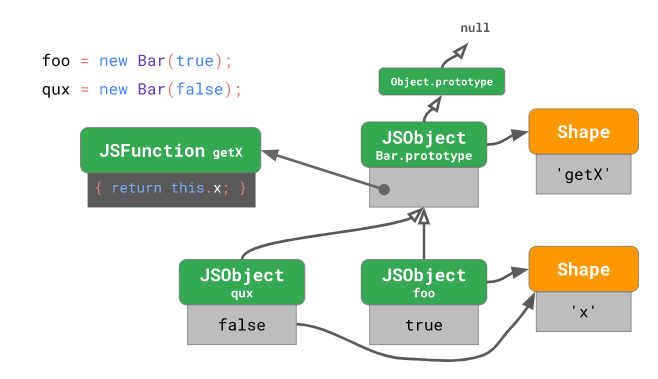
프로토타입 프로퍼티 접근
클래스를 정의하고 인스턴스를 생성하면 내부적으로 어떤 일이 일어나는지 살펴봤으니, 인스턴스의 메서드를 호출하면 어떤 일이 일어나는지 살펴봅시다.
아래 코드와 같이, 메서드를 호출하는 행위는 실제로 두 단계에 걸쳐 일어난다고 볼 수 있습니다:
const x = foo.getX();
// 실제로는 두 단계에 걸쳐 일어나는 것으로 볼 수 있습니다.
const $getX = foo.getX;const x = $getX.call(foo);즉,
- 메서드도 프로토타입의 프로퍼티이므로, 프로토타입 프로퍼티 탐색을 통해 호출하고자 하는 메서드를 찾습니다 (즉, 프로퍼티를 load 합니다).
- 원래의 인스턴스를 메서드의
this값으로 세팅한 뒤 메서드를 호출합니다.
첫 번째 과정부터 살펴봅시다. 우선 엔진은 메서드를 호출한 인스턴스(여기선 foo)의 “모양”에 getX 프로퍼티가 있는지 살펴봅니다. foo 인스턴스의 모양에서 getX 를 찾지 못했으니 프로토타입 체인을 따라 foo 인스턴스의 프로토타입인 Bar.prototype 객체의 “모양”을 살펴봅니다. Bar.prototype 의 “모양”으로 부터 getX 의 존재를 확인하였고, 그 오프셋이 0 이라는것 까지 확인했으니 엔진은 Bar.prototype 객체의 0번째 인덱스로 가서 최종적으로 찾고자 하는 getX 함수를 발견합니다. 이것이 바로 메서드를 찾는 과정인데, 앞서 살펴본 객체의 프로퍼티를 찾는 과정과 동일함을 알 수 있습니다:
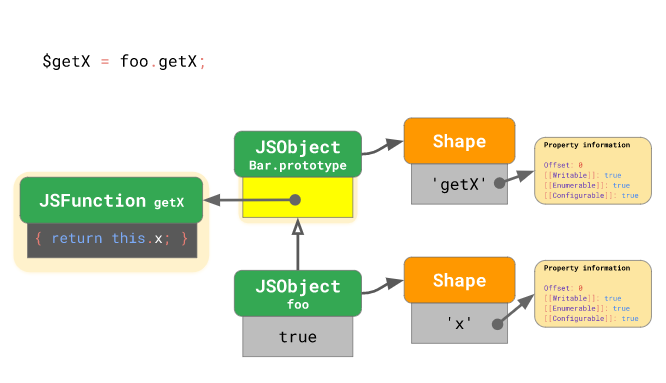
이전에 “모양”과 인라인 캐시를 통해 객체의 프로퍼티 접근을 최적화하는 기법을 살펴봤었는데요, 이러한 것들을 프로토타입에는 어떻게 적용할 수 있을까요?
앞서 getX 프로퍼티를 찾는 과정을 다시 예로 들자면, 프로토타입 프로퍼티 접근을 최적화하기 위해선 다음 세 가지를 체크했어야 합니다:
foo인스턴스의 “모양”이 바뀌지 않았는지? 즉,foo인스턴스에 프로퍼티를 추가하거나 제거하지 않고 초기의 상태(getX가 없는 상태)를 유지하는지 체크해야 합니다.- 자바스크립트에선 Object.setPrototypeOf() (혹은
__proto__) 을 통해 프로토타입 체인을 변경할 수 있으므로,foo인스턴스의 프로토타입이 원래의Bar.prototype인지(혹시 바뀌진 않았는지) 체크해야 합니다. Bar.prototype의 “모양”이 바뀌지 않았는지? 즉,Bar.prototype에 프로퍼티를 추가하거나 제거하지 않고 초기의 상태(getX가 있는 상태)를 유지하는지 체크해야 합니다.
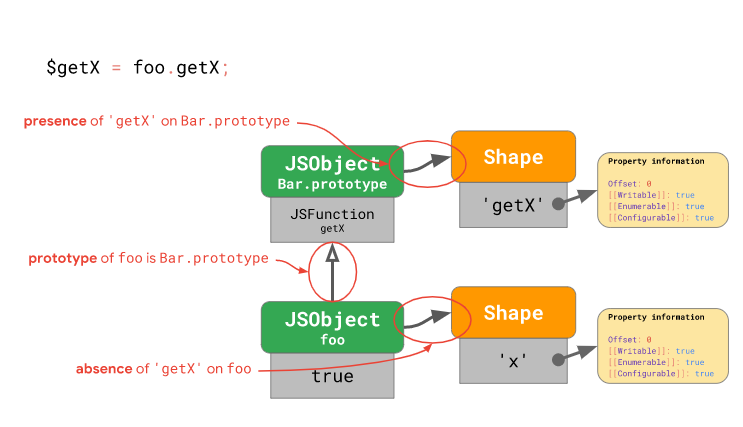
즉, 프로토타입 프로퍼티 접근을 최적화하기 위해선 인스턴스에 대해 1가지 체크를 해야하고, 우리가 찾고자 하는 프로퍼티를 가지는 프로토타입이 나올 때까지 각 프로토타입별로 2가지 체크를 해야 합니다. 다시 말해, 우리가 찾고자 하는 프로퍼티를 가지고 있는 프로토타입까지 도달하는데 N 개의 프로토타입을 거쳤다면 총 1 + 2N 번의 체크를 수행해야 하죠.
일반적으론 프로토타입 체인이 그리 길지는 않기 때문에 이 정도면 괜찮은 것 같지만, DOM과 같이 프로토타입의 체인이 훨씬 긴 경우 이야기가 좀 달라집니다:
const anchor = document.createElement('a'); // HTMLAnchorElement
const title = anchor.getAttribute('title');위 코드에선 HTMLAnchorElement 를 생성한 뒤 getAttribute 메서드를 호출하였는데, 이렇게 단순한 a 요소 하나의 프로토타입 체인에 존재하는 프로토타입의 개수는 무려 6개나 됩니다. 대부분의 DOM 관련 메서드는 HTMLAnchorElement 와 같은 요소에 직접 존재하지 않기 때문에 프로토타입 체인을 타고 거슬러 올라가야만 합니다:
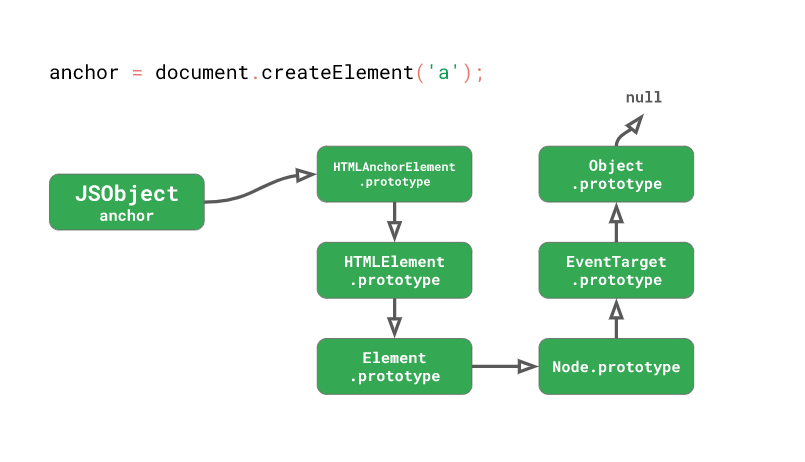
실제로 getAttribute 메서드는 Element.prototype 에 존재하는데, 그 말은 anchor.getAttribute() 를 수행할 때마다 엔진이 아래와 같은 작업을 수행해야 한다는 뜻이죠:
getAttribute메서드가anchor객체에 존재하지 않음을 확인.- 다음 프로토타입이
HTMLAnchorElement.prototype인지 확인한 뒤, 여기에getAttribute가 있는지 확인. - 그다음 프로토타입이
HTMLElement.prototype인지 확인한 뒤, 여기에getAttribute가 있는지 확인. - 그다음 프로토타입이
Element.prototype인지 확인한 뒤, 여기에getAttribute가 있는지 확인. - 최종적으로
getAttribute를 발견!
이렇게 DOM을 조작하는 코드는 흔하기 때문에 엔진은 프로토타입 프로퍼티에 접근하는데 필요한 체크를 줄이기 위해 트릭을 사용합니다.
앞서 살펴본 예시를 다시 살펴봅시다:
class Bar {
constructor(x) { this.x = x; }
getX() { return this.x; }
}
const foo = new Bar(true);
const $getX = foo.getX;우리가 원하는 프로퍼티를 찾을 때까지 총 1 + 2N 번의 체크를 수행했었어야 했습니다. “모양”에 프로퍼티가 존재하는지와 객체의 프로토타입이 원래의 프로토타입인지를 체크했었어야 했죠.
하지만 아래 그림처럼 객체에다 프로토타입 링크를 저장하는 것이 아니라 객체의 “모양”에 프로토타입 링크를 저장하면, 즉 객체가 프로토타입을 가리키는 것이 아니라 객체의 “모양”이 프로토타입을 가리키도록 하면 프로토타입이 원래의 프로토타입인지를 체크하는 과정을 생략할 수 있습니다:
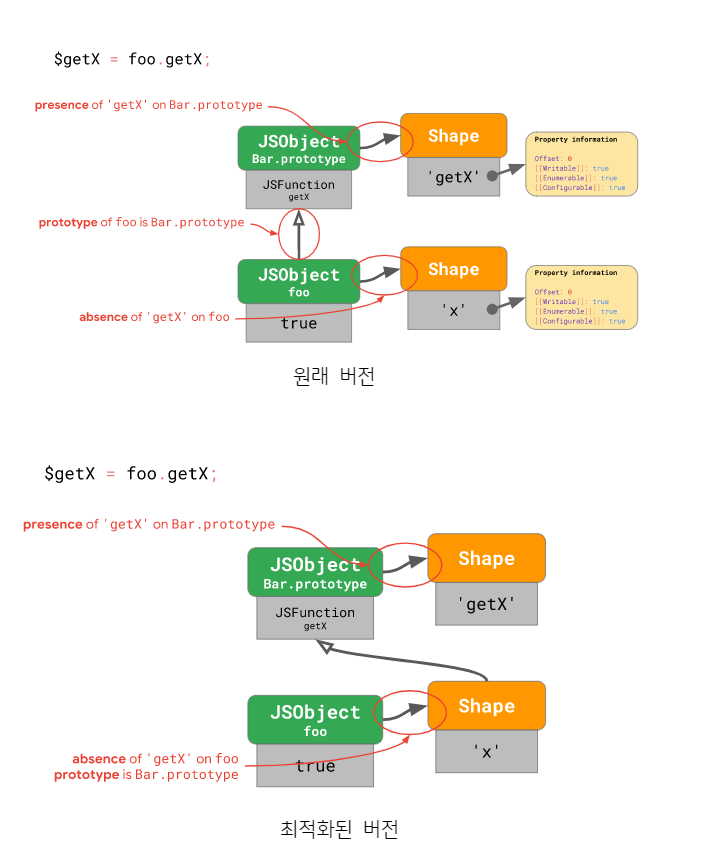
위와 같이 최적화된 버전의 경우, 프로토타입 체인이 바뀌면 “모양” 객체가 가리키는 프로토타입 링크 또한 바뀌기 때문에 프로토타입 체인을 통해 프로퍼티를 찾을 때 “모양”이 프로퍼티를 가지고 있는지만 체크하면 됩니다. 따라서 기존의 1 + 2N 번의 체크에서 1 + N 번의 체크로 줄어든 것이죠!
이에 더 나아가 동일한 프로퍼티를 연속으로 접근하는 경우 엔진은 이러한 체크를 상수 시간에 수행하는데, 어떻게 그럴 수 있는지 한 번 살펴봅시다.
유효 셀 (Validity cells)
자바스크립트의 각 프로토타입은 다른 프로토타입과는 공유하지 않는 자신만의 “모양”을 가집니다. 그리고 이러한 “프로토타입 모양”에는 ValidityCell 이라는 것이 존재합니다:
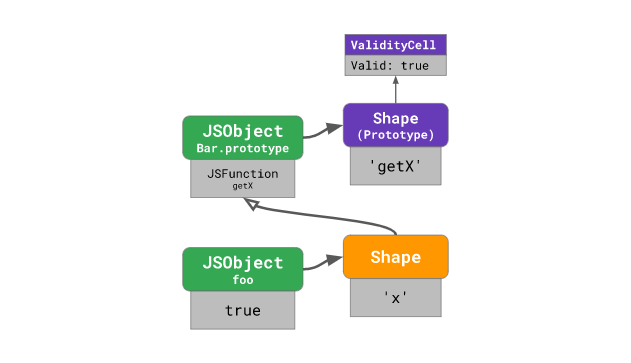
ValidityCell 은 처음엔 유효(Valid: true)한 상태였다가, 누군가 프로토타입 혹은 프로토타입 체인 상에서 상위에 있는 프로토타입을 변경하면 “무효화(invalidate)“됩니다. 이것이 어떻게 동작하는지 한 번 살펴봅시다.
연속된 프로토타입 프로퍼티 접근을 최적화하기 위해, 엔진은 인라인 캐시에 4가지 정보를 저장합니다:
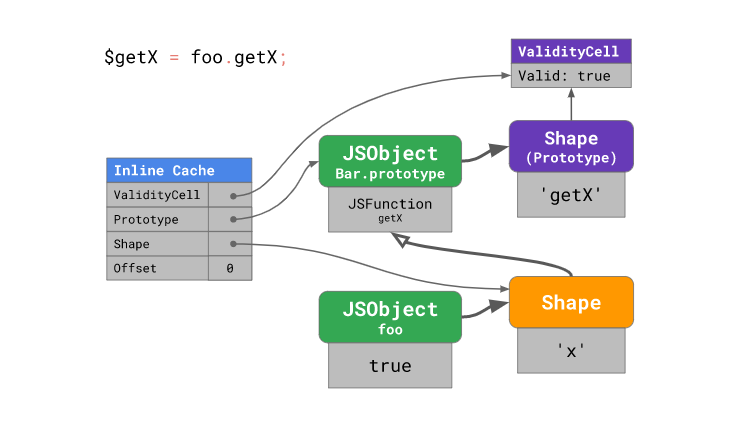
코드를 최초로 실행하면서 캐시 warm up을 수행할 때, 엔진은 아래 네 가지 정보를 인라인 캐시에 저장합니다:
- 프로퍼티의 오프셋.
- 프로퍼티를 가지고 있는 프로토타입.
- 인스턴스의 “모양”.
- 인스턴스의 “모양”이 가리키는 프로토타입(즉, 인스턴스의 바로 위에 있는 프로토타입)의 ValidityCell.
이후 인라인 캐시 히트가 발생하면 엔진은 인스턴스의 “모양”과 ValidityCell을 확인하는데, 만약 (ValidityCell이) 유효하다면 다른 과정을 다 건너뛰고 인라인 캐시에 저장된 프로토타입에 가서 오프셋 값을 가지고 프로퍼티를 바로 찾게 됩니다.
하지만 만약 프로토타입이 변경되었다면 새로운 “모양”이 할당되고 ValidityCell은 “무효화”(즉, Valid: false 로 바뀜) 됩니다. 그러면 이후에 캐시 미스가 발생하여 성능이 나빠지게 되는 것이죠:
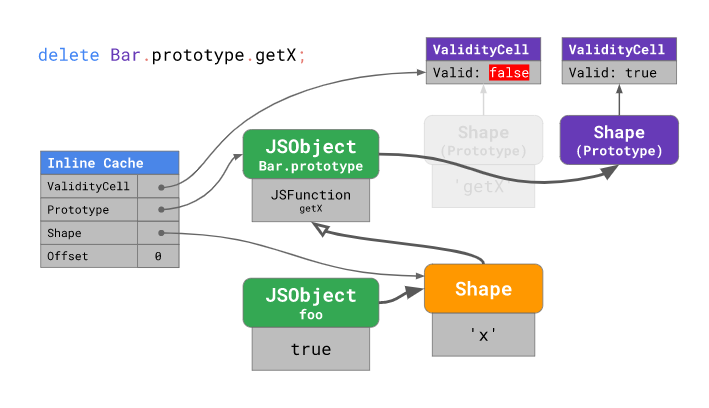
DOM 조작을 하는 예시로 다시 돌아가서 생각해보면, Object.prototype 과 같은 프로토타입을 변경하게 되면 비단 Object.prototype 의 ValidityCell을 무효화할 뿐만 아니라 Object.prototype 의 하위 프로토타입 모두를 무효화하게 됩니다:
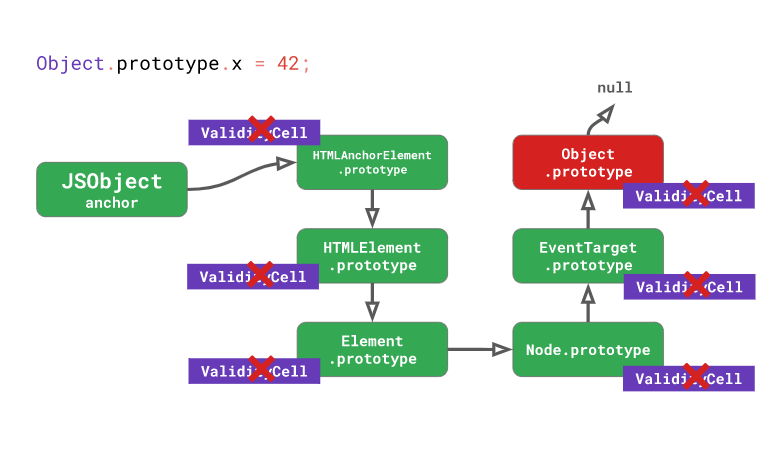
위 그림에서 볼 수 있듯이, Object.prototype 과 같이 프로토타입 체인 상에서 상위에 위치한 프로토타입을 수정하는 경우 하위에 존재하는 모든 프로토타입을 전부 무효화 해버립니다. 따라서 런타임에 프로토타입을 수정하게 되면 성능이 매우 나빠질 수도 있으니, 되도록 이러지 마세요!
마치며
여태껏 자바스크립트 엔진이 어떻게 내부적으로 객체를 저장하는지 살펴봤고, “모양”과 인라인 캐시 그리고 ValidityCell을 이용해서 어떻게 최적화를 하는지 살펴봤습니다. 이를 통해 알 수 있는 점은, 성능을 최대한으로 이끌어내기 위해선 (동일한 모양을 가질 수 있도록) 객체를 동일한 방식으로 초기화하는 것이 중요하다는 것, 그리고 최대한 프로토타입을 조작하지 않는 것이 중요하다는 것입니다.