브라우저의 동작 원리
카테고리: WebFebruary 21, 2022
⚠️ 이 포스트는 구글 크롬 브라우저를 기반으로 하고 있습니다. 구현 세부 사항은 브라우저마다 다를 수 있습니다.
브라우저의 주요 구성 요소
우선 브라우저의 구성 요소부터 살펴봅시다. 브라우저는 아래와 같이 크게 7가지의 구성 요소로 나눌 수 있습니다:
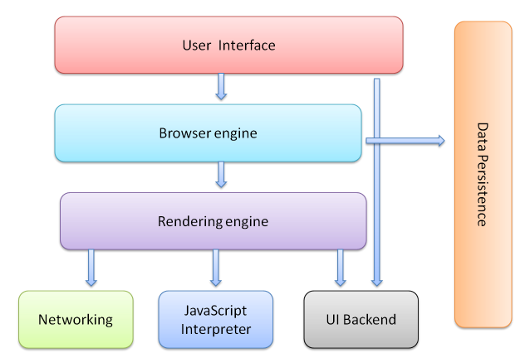
- 유저 인터페이스(User Interface): 사용자가 브라우저를 통해 상호 작용할 수 있도록 돕는 컴포넌트로, 주소 입력창·북마크·앞뒤 버튼 등과 같이 페이지가 보이는 영역을 제외한 부분입니다.
- 브라우저 엔진(Browser Engine): UI와 렌더링 엔진 사이에서 렌더링 상태를 조회하고, 렌더링 작업을 제어하기 위한 인터페이스를 제공합니다.
- 렌더링 엔진(Rendering Engine): HTML, CSS 등을 분석하여 컨텐츠를 화면에 표시하는 역할을 수행합니다. 렌더링 엔진에는 Blink(크롬), Webkit(사파리), Gecko(파이어폭스), Trident(IE) 등이 있습니다.
- 네트워킹(Networking): HTTP 요청과 같은 네트워크 작업을 수행합니다. DNS 조회, TCP 연결 등의 작업도 수행하며 브라우저별로 6~10개의 스레드를 통해 동시에 TCP 연결을 생성해 리소스를 다운로드할 수 있습니다.
- UI 백엔드(UI Backend): 콤보박스·드랍박스 등 기본적인 UI 컴포넌트들을 제공합니다.
- 자바스크립트 해석기(JavaScript Interpreter): 말 그대로 자바스크립트 코드를 분석·해석하는 역할을 수행합니다. 자바스크립트 엔진에는 V8(크롬), SpiderMonkey(파이퍼폭스), Chakra(MS 엣지), JavaScriptCore(사파리) 등이 있습니다.
- 데이터 저장소(Data Persistence): 데이터 지속성(persistence)을 유지하기 위한 컴포넌트로, 쿠키와 같은 데이터를 로컬 디스크에 저장합니다. HTML5에선 로컬 스토리지, Indexed DB, WebSQL 등을 이용하여 더 많은 데이터를 저장할 수 있습니다.
브라우저의 여정
그럼 이제 본격적으로, 브라우저 주소창에 도메인(예를 들어 www.google.com)을 입력하면 어떤 일들이 일어나는지를 살펴봅시다:

네비게이션

우선 첫 번째로 일어나는 일은, 올바른 장소로 찾아가는(navigate) 것입니다. 특정 웹 페이지를 찾아간다는 말은 해당 페이지에 대한 데이터가(즉, 자원) 어디에 있는지를 찾아낸다는 의미입니다.
DNS Lookup
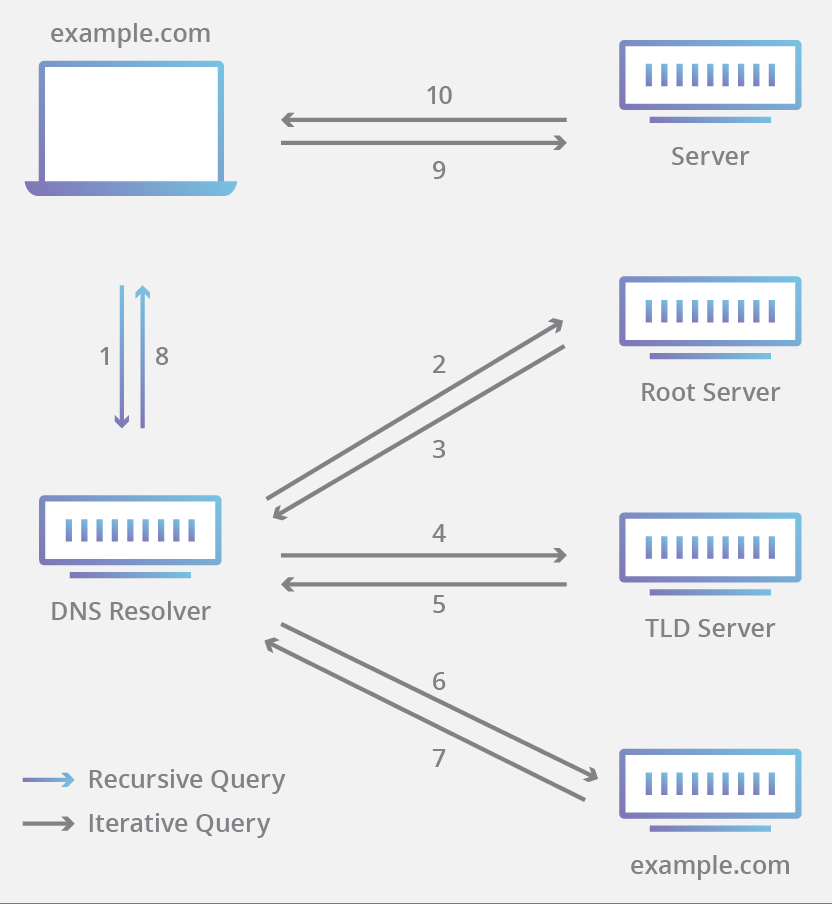
사람에게 웹 페이지란 google.com과 같은 도메인 이름이지만, 컴퓨터는 오직 0과 1밖에 모르기 때문에 도메인 이름 “문자열”을 IP 주소로 변환해야만 합니다. 이렇게 도메인 이름을 IP주소로 변환하는 과정을 DNS lookup(혹은 DNS 쿼리) 이라고 합니다.
www.google.com 도메인에 대한 DNS lookup 과정을 간략하게 나타내면 다음과 같습니다:
-
우선 해당 도메인의 IP주소에 대한 캐시가 있는지 살펴봅니다:
- 제일 먼저 브라우저 캐시부터 살펴봅니다.
- 브라우저 캐시가 없으면 (시스템 콜을 통해) OS 캐시를 살펴봅니다.
- OS 캐시에도 없으면 라우터와 통신하여 라우터 캐시를 살펴봅니다.
- 만약 라우터 캐시에도 없으면 ISP의 DNS 서버에 있는 ISP 캐시를 살펴봅니다.
-
만약 위 과정에서 최종적으로 캐시를 발견하지 못했다면 브라우저는 DNS resolver에게 요청하여 도메인(URL)에 대한 IP 주소를 얻습니다:
- 우선 resolver가 DNS root 네임 서버 (
.) 에게 요청합니다. - root 네임서버는
.com,.net과 같은 TLD DNS 네임서버의 주소를 반환합니다. www.google.com을 검색하는 경우,.comTLD DNS 네임 서버 주소를 반환하게 될 것입니다. - resolver는 이제 TLD 네임서버에게 요청을 보냅니다.
- TLD 네임서버는 authoritative 네임 서버(도메인 네임 서버)의 주소를 반환합니다. www.google.com의 경우, google.com 네임서버의 주소를 반환하게 될 것입니다.
- resolver는 마지막으로 authoritative 네임서버에게 요청을 보냅니다.
- authoritative 네임서버는 요청받은 URL의 IP주소(여기선 www.google.com의 IP 주소)를 반환합니다.
- 우선 resolver가 DNS root 네임 서버 (
실제로는 각 레이어마다 캐시를 사용하기 때문에 이 과정은 일반적으로 매우 빠르게 일어납니다.
TCP Handshake
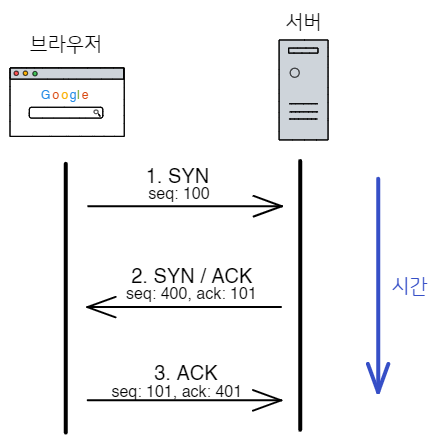
이제 IP 주소를 알아냈으니, 브라우저는 IP 주소에 해당하는 서버와 통신할 준비를 합니다. 이때 서버와 연결을 하기 위해 사용되는 프로토콜에는 여러 종류가 있지만, HTTP 요청에는 주로 TCP가 사용됩니다.
브라우저는 TCP 3-way handshake를 통해 IP 주소에 해당하는 서버와 연결을 합니다. 대략적인 과정은 다음과 같습니다:
- 클라이언트(브라우저)가 서버에게 새로운 연결을 요청하기 위해 SYN 패킷을 보냅니다.
- 서버가 새로운 연결을 할 수 있는 상태라면, SYN/ACK 패킷을 클라이언트로 보내 SYN 패킷에 대한 응답을 합니다.
- 마지막으로, 클라이언트는 SYN/ACK에 대한 응답으로 ACK 패킷을 서버로 보냅니다.
TLS Negotiation
만약 HTTPS 프로토콜을 사용하는 경우, 서버와 통신을 하기 위해 한 가지 과정을 더 거쳐야 합니다. 여기서 HTTPS는 TLS(SSL)를 사용하여 일반적인 HTTP 요청/응답을 암호화 하는 프로토콜입니다.
HTTPS를 사용하여 안전한 통신을 하기 위해선 또 다른 handshake 과정을 수행해야만 하는데, 이를 TLS handshake (TLS negotiation) 라고 합니다. 이 과정에선 다음의 일들이 일어납니다:
- 어떤 TLS 버전(TLS 1.0, 1.2, 1.3, etc.)을 사용할 것인가를 결정합니다.
- 어떤 cipher suite를 사용할 것인가를 결정합니다.
- 서버의 공개키(public key)와 SSL certificate의 전자 서명을 통해 서버의 신원을 인증합니다.
- Handshake 이후 symmetric encryption을 사용하기 위해 세션 키를 생성합니다.
TLS handshake에 대한 더욱 자세한 내용은 여기를 참고하세요.
Fetching
이제 TCP 연결을 맺었으니(HTTPS의 경우 TLS 설정까지), 브라우저는 HTTP(S) 프로토콜을 이용하여 서버로부터 HTML 파일을 다운로드 받습니다.

HTTP Request
페이지를 가져오기 위해 브라우저는 서버에게 idempotent (간단히 말하자면, 같은 입력에 대해선 항상 같은 출력이 나온다는 뜻)한 요청을 보냅니다. 이때 HTTP의 GET 메소드를 사용합니다.
HTTP GET 메소드를 간단히 말하자면, 주어진 URI가 가리키는 서버의 데이터를 요청하는 것이라고 할 수 있습니다.
HTTP GET을 사용하면 다음과 같이 서버에게 HTTP Request를 보냅니다:
GET / HTTP/2
Host: www.google.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Accept-Language: en-GB,en;q=0.5
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Upgrade-Insecure-Requests: 1
Cache-Control: max-age=0
TE: Trailers이러한 요청을 받은 서버는 요청과 관련된 헤더와 데이터를 다음과 같이 HTTP Response 형식으로 응답합니다:
HTTP/2 200 OK
date: Sun, 18 Jul 2021 00:26:11 GMT
expires: -1
cache-control: private, max-age=0
content-type: text/html; charset=UTF-8
strict-transport-security: max-age=31536000
content-encoding: br
server: gws
content-length: 37418
x-xss-protection: 0
x-frame-options: SAMEORIGIN
domain=www.google.com
priority=high
X-Firefox-Spdy: h2이때 HTML 문서 데이터는 response의 body에 포함되어 전달됩니다.
더 많은 HTTP 메소드에 대해선 RFC7231 Section 8.1.3을 참고하세요.
중요 렌더링 경로 (Critical Rendering Path, CRP)
브라우저의 렌더링 엔진이 웹 페이지를 분석해서 화면에 표시하는 작업들은 선후 관계가 비교적 명확하므로 일반적으로 단일 스레드(주로 메인 스레드)에 의해 수행됩니다. 예를 들어 HTML이 해석되지 않으면 CSS와 자바스크립트가 수행될 수 없고, DOM이 만들어지지 않으면 브라우저가 화면을 구성할 수 없으며, 화면을 구성하지 못하면 결국 페이지를 그리지 못하게 되는 것이지요. 따라서 이러한 일련의 작업을 브라우저가 어떠한 순서로 처리하는지 이해하는 것은 웹 최적화뿐만 아니라 웹 개발에도 매우 중요하다고 할 수 있습니다.
| 📌 |
|---|
| 여기서 critical의 의미는 페이지를 처음 그리는데 필요한 자원, 즉 페이지의 초기 렌더링 과정을 blocking 하는 자원을 의미합니다 (parser-blocking한 자원). 주로 HTML, CSS, 스크립트 파일이 critical한 자원이며 이미지 같은 자원들은 일반적으로 “critical”하게 취급되지 않습니다 (따라서 초기 렌더링을 blocking하지 않습니다). 물론 critical 하지 않은 자원들도 빠르게 다운로드 해야겠지만요! |
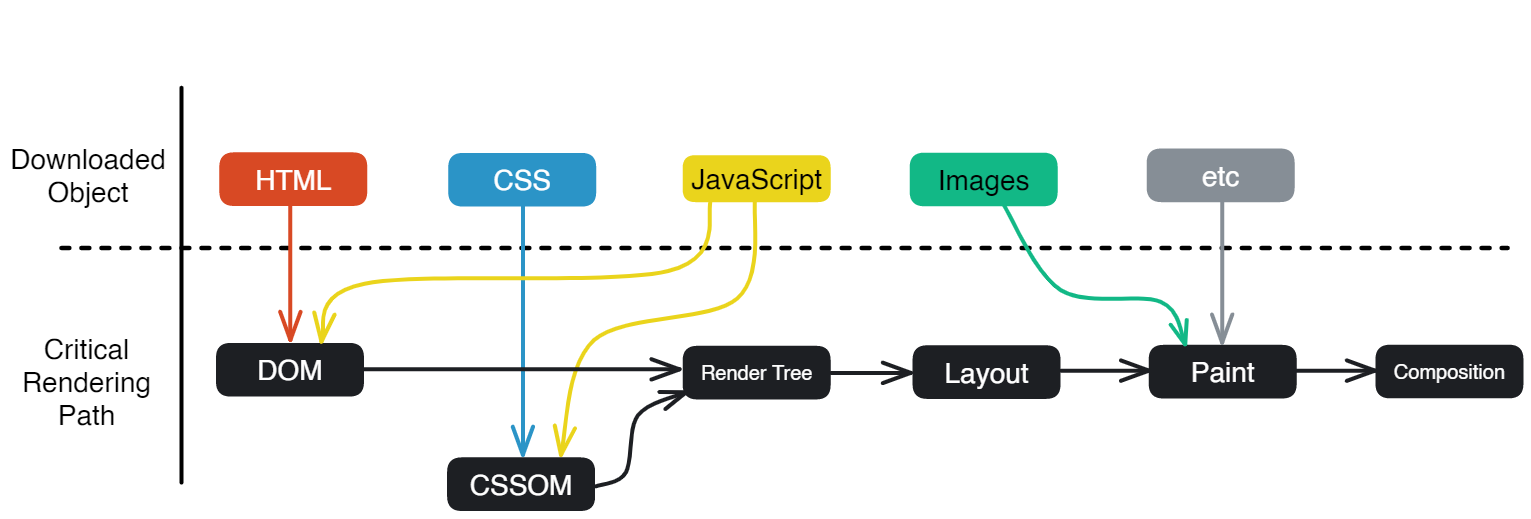
이제 브라우저가 CRP를 어떻게 수행하는지 살펴봅시다.
파싱

앞선 네비게이션 및 fetching 과정들을 통해 서버로부터 응답을 받기 시작하면 브라우저는 데이터를 파싱(분석)하기 시작합니다. 파싱 과정은 쉽게 말해 네트워크를 통해 서버로부터 전달받은 HTML, CSS 데이터를 DOM과 CSSOM(곧 살펴볼 예정)으로 변환하는 과정이라고 할 수 있습니다.
DOM 트리 생성
우선 브라우저는 다운로드 한 HTML 파일을 분석하여 DOM(Document Object Model)이라는 객체 모델로 변환합니다. HTML, XML과 같이 마크업 언어로 작성된 문서들은 사람이 이해하긴 쉽지만, 컴퓨터가 사용하기엔 어려운 구조입니다. 따라서 문서를 프로그래밍 언어(주로 자바스크립트)로 쉽게 조작할 수 있게 트리 형태로 구조화한 것이 DOM 트리라고 할 수 있습니다. 일종의 API인 셈이지요.
HTML을 파싱하는 과정은 프로그래밍 언어를 파싱하는 일반적인 과정과는 사뭇 다릅니다. 몇 가지 이유는 다음과 같습니다:
- HTML은 에러를 너그럽게 용납하기 때문입니다. 예를 들면 태그를 열고서 제대로 닫지 않는다든가(
<p>123), 클래스 이름을 적을 때 따옴표를 쓰지 않는다든가(<div class=abc></div>), 중첩이 잘못 되었다든가(<main><aside></main></aside>)와 같은 경우들 대부분은 에러 없이 거의 정상적으로 표시됩니다. - HTML 파싱 프로세스 자체가 재진입(re-entrant)하는 특성을 갖습니다. 즉, 파싱 중에 자바스크립트의
document.write()등을 통해 새로운 요소가 추가될 수 있으므로 파싱 단계를 시작할 때의 최초 입력(원래의 HTML 문서)이 변경될 수 있습니다.
이러한 이유로 인해 기존의 파싱 기법으로는 HTML을 해석할 수가 없기 때문에 브라우저들은 커스텀 파서를 구현하여 사용합니다.
HTML 파싱 알고리즘은 HTML5 스펙에 명시되어 있습니다. HTML 파싱 알고리즘은 크게 토큰화(tokenization)와 트리 구축(tree construction) 단계로 나눌 수 있습니다:
- 토큰화 단계: 위 HTML5 스펙에 따라 HTML 문서를 토큰으로 분리합니다. HTML 토큰에는 시작 태그(
<), 종료 태그(>), 속성 이름, 속성값 등이 있습니다. - 트리 구축 단계: 파싱된 토큰들을 DOM 트리 형태로 변환하는 과정입니다.
앞서 말했듯이 DOM 트리는 HTML 문서의 구조를 나타내는 API 입니다. 이때 트리 형태로 나타내는 이유는 기본적으로 HTML에선 서로 다른 태그 간의 관계를 정의하고 있기 때문입니다. 어떤 태그가 다른 태그 안에 중첩되는 것처럼요.
DOM 트리의 루트는 <html> 태그이며 트리의 각 요소를 DOM 노드라고 합니다. 당연한 말이겠지만 요소의 개수가 많을수록 DOM 트리를 만드는 데 시간이 더욱 오래 걸립니다. 파싱이 완료된 DOM 트리는 일반적으로 아래와 같은 형태가 됩니다:
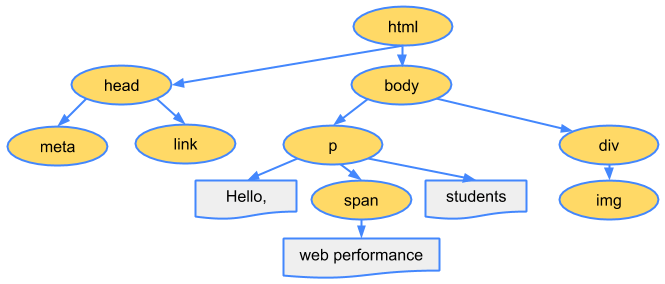
HTML을 파싱하는 과정에서 브라우저 파서가 이미지와 같이 HTML 파싱을 방해하지 않는 리소스를 만나게 되면 백그라운드에서 해당 리소스를 다운받음과 동시에 파싱을 계속해서 이어나갑니다. 하지만 <script> 태그를 만나게 되면 이야기가 좀 달라집니다.
기본적으로 브라우저는 <script> 태그를 만나게 되면 HTML 파싱을 일시 중지하고 해당 스크립트를 실행한 다음 다시 파싱을 재개합니다. 그 이유는 document.write()와 같이 자바스크립트를 통해 DOM을 조작할 수 있기 때문이죠. 만약 <script src="...">와 같이 외부 스크립트 파일이라면 해당 스크립트 파일을 다운로드하여 실행을 완료할 때까지 파싱을 일시 중지하게 됩니다.
물론 pre-load scanner 덕분에 이 딜레이를 단축할 수는 있으나, 스크립트 파일이 많은 경우 여전히 이로 인해 렌더링이 지연될 수 있어 웹 성능에 악영향을 미칠 수 있습니다. pre-load scanner에 관한 내용은 여기와 여기를 참고해 주세요.
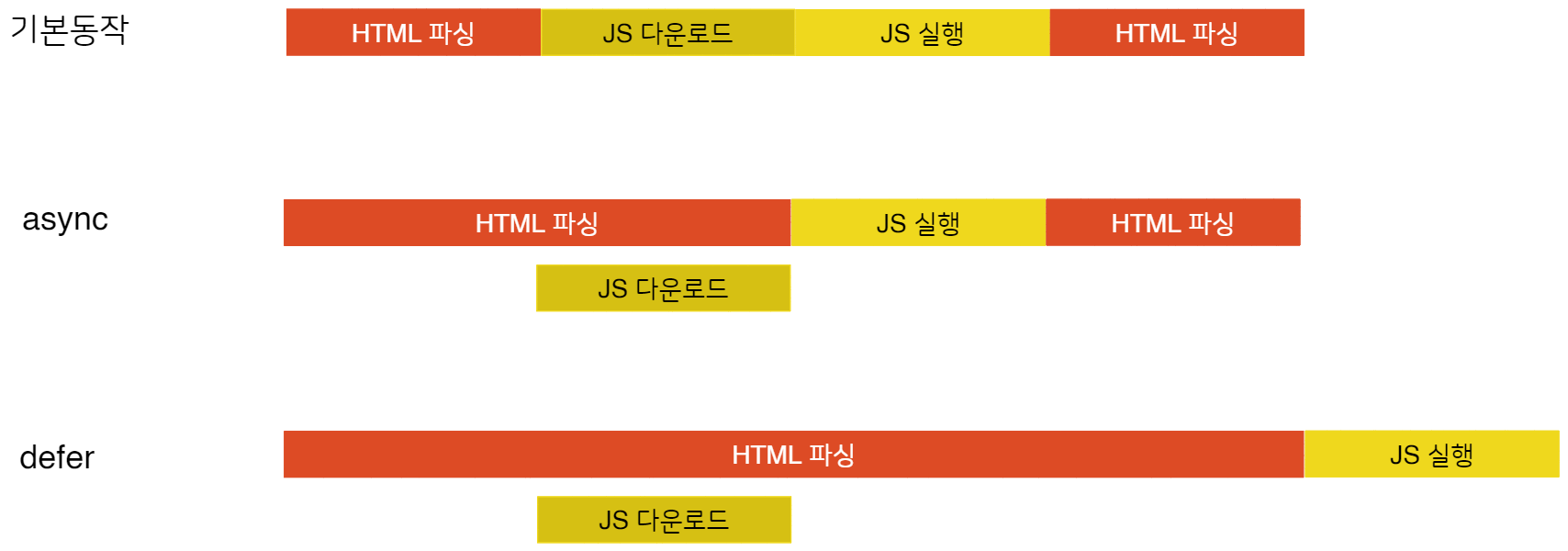
물론 초기 렌더링에 관여하지 않는 스크립트 파일의 경우, async, defer 속성을 사용하여 이러한 동작을 변경할 수도 있습니다. 이 속성들의 동작을 그림으로 나타내면 다음과 같습니다:
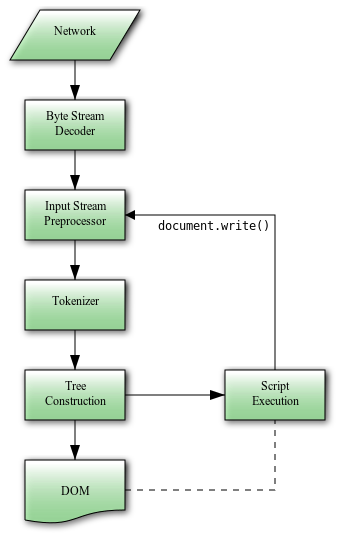
HTML 파싱 과정을 종합하여 나타내면 다음 도식과 같습니다. 개인적으로 이 그림에 앞에서 말한 “re-entrant”한 특성이 잘 나타나있다고 생각하는데, 이러한 특성으로 인해 HTML 파싱의 기본 동작이 스크립트를 실행하는 동안에 파싱을 일시 중단하는 것이라고 생각합니다:
CSSOM 트리 생성
HTML과 마찬가지로 CSS 파일도 파싱해서 트리 구조를 만드는데, 이렇게 만들어진 CSS 파일의 트리 구조를 CSSOM(CSS Object Model) 트리라고 합니다. 쉽게 말해 CSS 버전의 DOM이라고 할 수 있겠습니다.
CSSOM의 각 노드에는 해당 노드가 타겟으로 하는 DOM 요소의 스타일 정보가 담겨 있습니다. DOM과 마찬가지로 CSSOM이 트리 구조인 이유는 CSS의 “Cascading”한 특성 때문입니다. 페이지의 특정 요소에 최종적으로 적용할 스타일을 계산할 때, 브라우저는 우선 해당 요소에 적용 가능한 가장 일반적인(general) 규칙부터 시작하여 점점 구체적인(specific) 규칙을 적용해 나갑니다. 예를 들어 <body> 요소 내에 중첩된 <p> 요소에 대해, 우선 <body> 요소의 스타일부터 적용하고 이후 <p> 요소의 스타일로 덮어씌우는 것처럼 말이죠.
또한 브라우저마다 기본적으로 user agent stylesheet 을 제공합니다. 따라서 브라우저는 제일 처음엔 이 규칙을 적용하고, 이후 개발자가 작성한 스타일을 적용해 나갑니다. 만일 user agent stylesheet에도 없는 스타일 속성의 경우 W3C CSS standard에 정의된 기본 스타일 속성값이 적용됩니다.
이렇게 만들어진 CSSOM 트리의 예시는 아래와 같습니다:
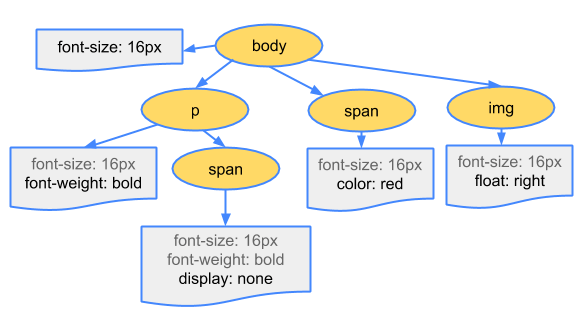
여담으로, 더 명시적인(more specific) CSS 셀렉터는 덜 명시적인(less specific) 셀렉터보다 느립니다. 예를 들어 .bar .foo {} 셀렉터는 .foo {} 셀렉터보다 느린데, 그 이유는 첫 번째 셀렉터에서 .foo는 조상으로 .bar를 가지는지 DOM을 타고 올라가서 살펴봐야 하기 때문입니다. 즉, 셀렉터가 더욱 명시적일수록 브라우저가 해야 할 일이 많아지게 되어 더 느려집니다. 하지만 애초에 CSSOM을 만드는 과정이 워낙 빠르기 때문에 이를 최적화할 가치는 딱히 없습니다(최적화를 한다고 해도 그 차이가 마이크로초 단위일 겁니다😂). 항상 성능을 측정해보고, 그다음 최적화를 해야 합니다.
앞서 HTML이 에러를 너그럽게 용납하는 것과는 다르게, CSS를 파싱할 땐 엄격한 구문 검사가 적용됩니다. 파싱 방법이 다르다 보니 사용하는 파서와 동작 스레드도 다르고, 이로 인해 HTML 파싱 과정이 CSS 파싱 과정에 의해 방해받진 않습니다. 또한, 기본적으로 브라우저가 HTML을 파싱할 때 <link> 태그를 만나게 되면 해당 CSS 파일 다운로드를 요청하고 계속해서 HTML 파싱을 이어나갑니다.
렌더링
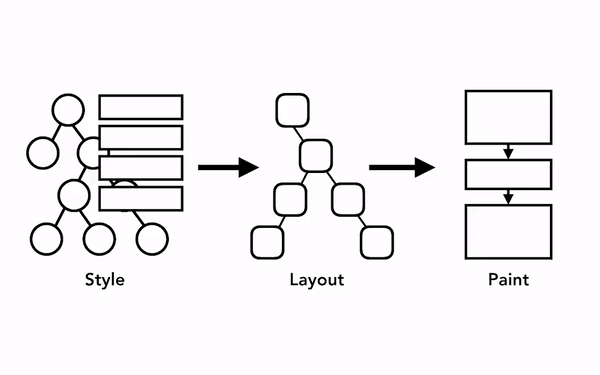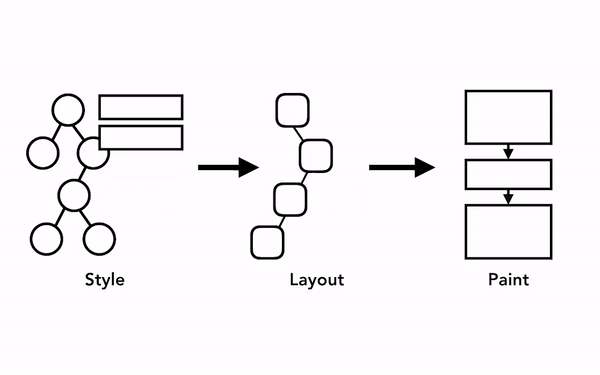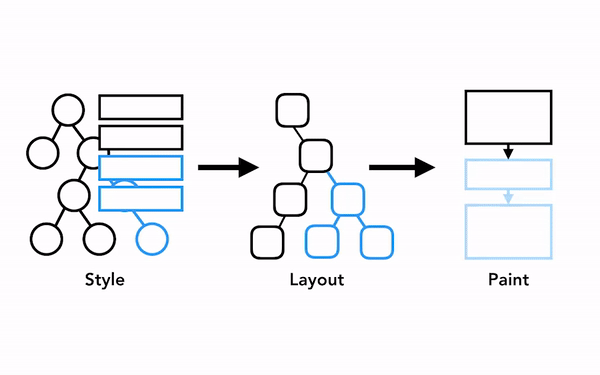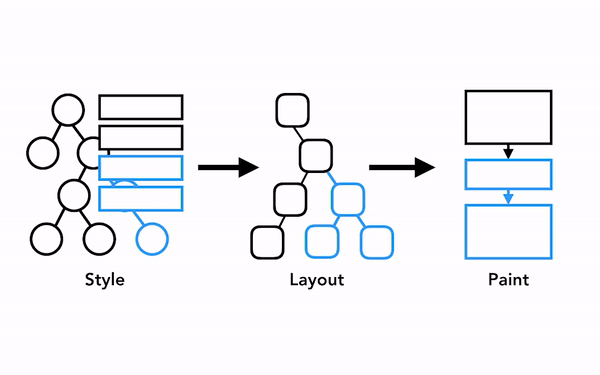
이제 서버로부터 다운받은 HTML, CSS 파일을 각각 DOM, CSSOM으로 변환했다면 이제 이들을 이용하여 실제 화면에 그려낼 차례입니다. 렌더링의 각 단계를 순서대로 나타내면 다음과 같습니다:

Render 트리 구축
이 단계에선 DOM 트리와 CSSOM 트리를 합쳐 렌더 트리(render tree)를 만듭니다. 렌더 트리는 말 그대로 화면에 렌더링할 요소들의 정보들을 나타내는 자료 구조라고 보시면 될 것 같습니다.
렌더 트리를 구축하는 과정은 일반적으로 다음과 같습니다:
-
DOM의 루트부터 시작하여 “visible” 한 요소를 탐색해 나갑니다.
- 이때, 개인적으로 “visible” 한 요소의 의미를 “실재하는(existence)” 요소라고 생각합니다. 즉, 화면에 “실재(實在)“하는 요소들만 렌더 트리의 노드로 포함하는 것이죠. 실재하지 않는 요소라는 말은, 요소가 눈에 보이지도 않을 뿐 더러 화면 상에 아무런 공간도 차지하지 않는다는 것입니다.
- 다시 말하자면
<head>,<meta>,<link>와 같은 HTML 요소들과display: noneCSS 속성이 적용된 요소들은 렌더 트리에 포함되지 않습니다. 이들은 화면 상에 “실재”하지 않기 때문이죠 (눈에 보이지도 않고 실제로 공간을 차지하지도 않음). - 하지만
visibility: hidden과opacity: 0CSS 속성이 적용된 요소의 경우 우리 눈에는 보이지 않지만, 여전히 화면 상에서 공간을 차지하고 있기 때문에 렌더 트리에 포함됩니다. 또한::before,::after와 같은 CSS pseudo 클래스의 경우, DOM에는 존재하지 않지만, 화면 상에서 공간을 차지하는 친구들이므로 렌더 트리에 포함됩니다.
- 각 visible한 요소에 대해 CSSOM 규칙을 찾아 적용합니다.
이렇게 만들어진 렌더 트리의 각 노드는 HTML 요소와 해당 요소에 최종적으로 적용되는 스타일 정보를 갖고 있습니다. 렌더 트리를 그림으로 나타내면 아래와 같습니다:
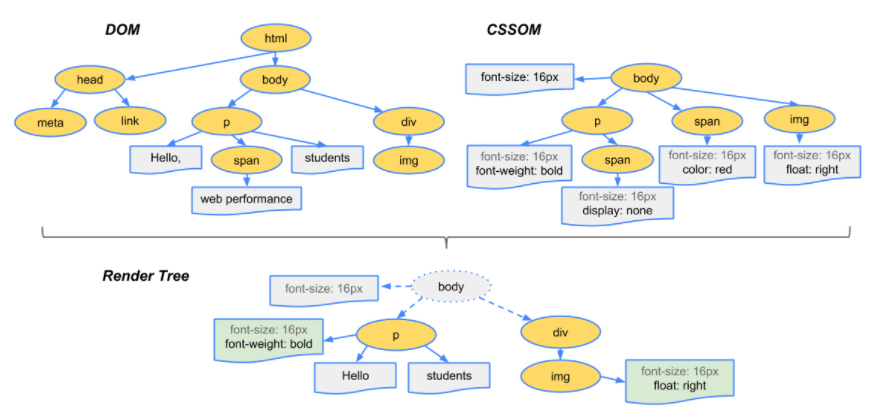
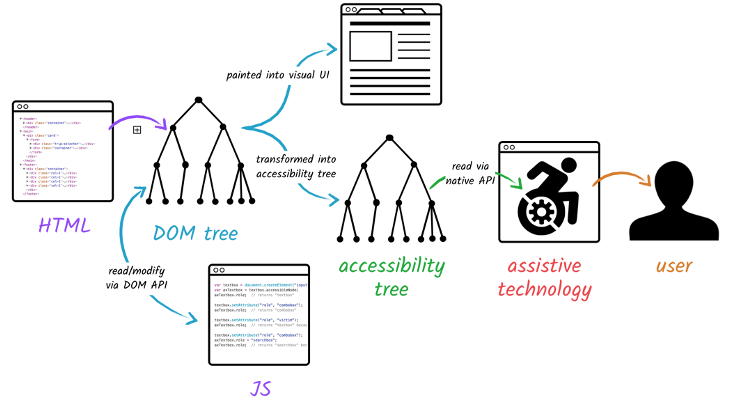
접근성 트리 구축
브라우저는 또한 보조 기기(assistive device)가 사용하는 접근성 트리(Accessibility Object Model, AOM)를 구축합니다. AOM 트리가 만들어지기 전까진 스크린 리더기에 컨텐츠가 표시되지 않습니다.
레이아웃
이제 문서의 구조와 각 요소의 스타일까지 모두 계산했으니, 요소들의 위치 및 크기를 계산할 시간입니다. 아래 예제를 살펴봅시다:
<!-- 출처: https://developers.google.com/web/fundamentals/performance/critical-rendering-path/render-tree-construction -->
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="width=device-width,initial-scale=1" />
<title>Critial Path: Hello world!</title>
</head>
<body>
<div style="width: 50%">
<div style="width: 50%">Hello world!</div>
</div>
</body>
</html>위 HTML의 <body> 태그에는 두 개의 중첩된 <div> 가 있습니다. 첫 번째(부모) <div>는 뷰포트 너비(width)의 50%가 적용되고, 두 번째(자식) <div>의 너비는 첫 번째(부모) 요소 너비의 50%가 적용됩니다. 즉, 두 번째 <div>는 최종적으로 뷰포트 너비의 25%가 적용되는 셈이지요:
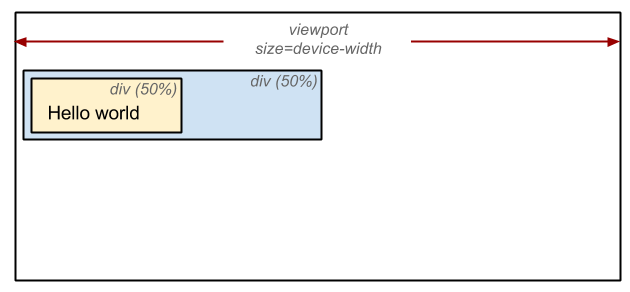
레이아웃 단계의 결과는 뷰포트 내의 각 요소의 정확한 위치와 크기를 적용한 박스 모델입니다. %, em, vw와 같은 상대 치수들은 절대 단위인 픽셀로 변환됩니다.
웹 페이지의 레이아웃을 결정하는 작업은 어렵습니다 (크롬 개발팀 안에 레이아웃 전담팀이 따로 있을 정도죠). 단순히 위에서 아래로 내려오는 블록 영역 하나만 있는 웹 페이지의 레이아웃을 결정할 때도 폰트의 크기는 얼만지, 줄 바꿈은 어디서 해야 하는지 등을 고려해야만 합니다. 왜냐면 이러한 요소들이 문단의 크기와 모양에 영향을 미치기도 하고, 다음 단락의 위치에도 영향을 주기 때문이죠:

이렇게 레이아웃 단계를 거치고 나면 레이아웃 트리(layout tree)가 만들어집니다. 이 트리의 각 노드는 해당 요소의 x, y 좌표 및 박스 영역(bounding box)의 크기와 같은 정보를 갖습니다.
레이아웃과 dirty bit 시스템
작은 변화에도 전체 요소의 레이아웃을 다시 계산하는 것은 너무 비효율적이므로, 브라우저들은 dirty bit를 사용하여 변경사항이 있는 요소와 그 자식 요소들만 dirty bit로 검사하여 꼭 필요한 요소들만 다시 계산합니다.
레이아웃 과정을 reflow, 혹은 browser reflow라고도 합니다 (주로 파이어폭스에서 이 용어를 사용합니다만 본질적으로 앞서 살펴본 layout과 똑같습니다). 화면을 스크롤 하거나, 화면을 줄이거나 늘리는 등 크기를 바꾸거나, DOM을 조작하는 등의 행동을 할 때 reflow 과정이 일어납니다. 이 리스트에서 레이아웃 과정을 발생시키는(trigger) 이벤트들을 보실 수 있습니다.
페인트
이제 DOM·스타일·위치 및 크기까지 알게 되었지만, 여전히 화면을 그리기엔 역부족입니다. 그럼 뭘 더해야 할까요?
바로 각 요소들의 그리기 순서를 정하는 것입니다. 어떤 그림을 똑같이 따라 그린다고 해봅시다. 그림에 있는 요소들의 위치·크기·모양·색상 등을 알고 있지만, 이들을 어떤 순서로 그릴 것인가 또한 결정해야 합니다:
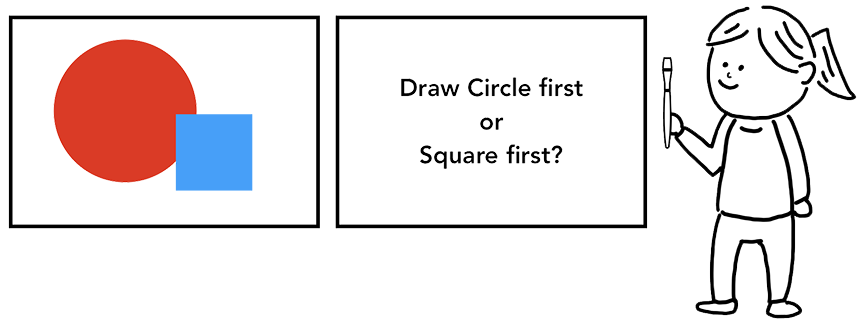
예를 들어, 만약 어떤 요소에 z-index 속성이 적용된 상태라면, HTML에 나타난 순서대로 요소들을 그리면 우리가 원하는 결과대로 나오지 않을 수 있습니다:
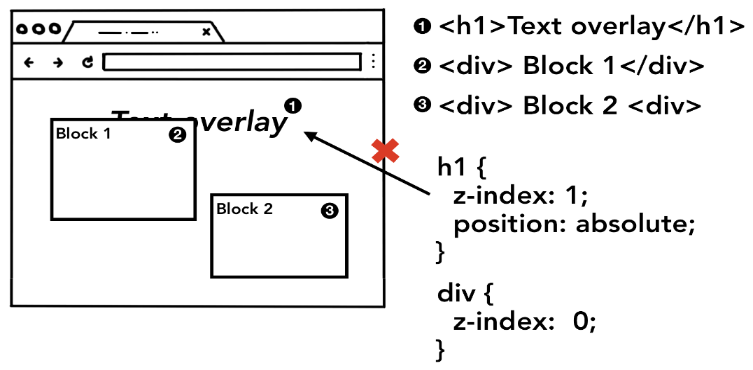
따라서 페인트 단계에서 메인 스레드는 레이아웃 트리를 이용하여 페인트 기록(paint records)을 만듭니다. 페인트 기록은 페인팅 과정을 어떻게 수행할지를 기록한 노트라고 볼 수 있습니다. “바탕 먼저 그리고, 그 다음 텍스트, 그 다음 사각형” 과 같이 말이죠. <canvas>를 사용해보셨다면 이와 비슷한 경험을 해보신적이 있으실 겁니다.
CSS2 스펙에 명시된 페인팅 순서는 여기서 보실 수 있습니다.
합성
이제 DOM·스타일·레이아웃 및 그리기 순서까지 전부 알아냈으니 남은 것은 이 정보들을 이용하여 화면을 그리면 됩니다. 이러한 정보를 화면에 픽셀로 찍어내는 작업을 래스터화(rasterization) 이라고 합니다.
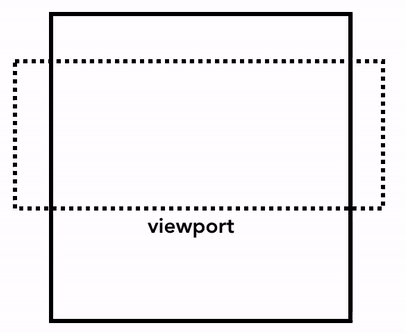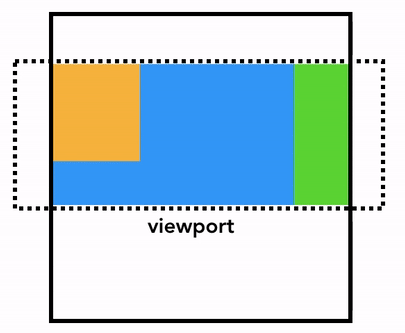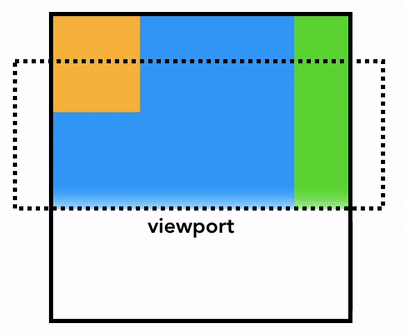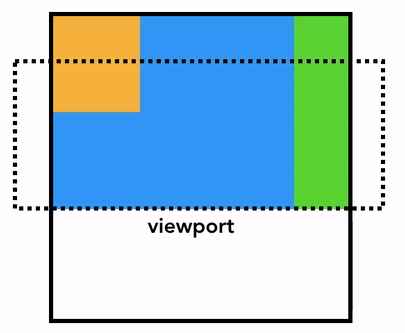
그럼 어떻게 그릴까요? 🤔 가장 단순한 방법은 뷰포트 내의 정보들을 그려놓고, 이후에 유저가 페이지를 스크롤 하면 이전에 래스터화된 부분은 위로 옮기고 새로 생겨난 빈 공간을 채우는 방식입니다. 초창기 크롬이 이러한 방식으로 동작했었습니다:
하지만 현대의 브라우저들은 합성(composition) 이라는 더욱 정교한 기법으로 화면을 그립니다. 합성이란 페이지를 레이어(layer)로 나눈 다음, 각 레이어를 따로따로 래스터화한 뒤 다시 하나의 페이지로 합치는 기법입니다. 만약 유저가 스크롤을 하면 레이어들은 이미 래스터화가 완료된 상태이므로 브라우저는 단순히 레이어들을 새로 합치기만 하면 됩니다. 애니메이션도 이와 같은 방식으로 레이어들을 새로 합쳐서 구현할 수 있습니다:
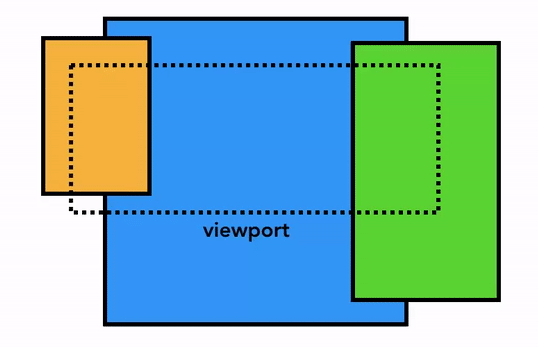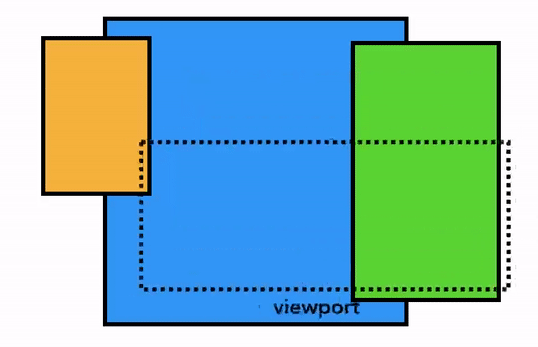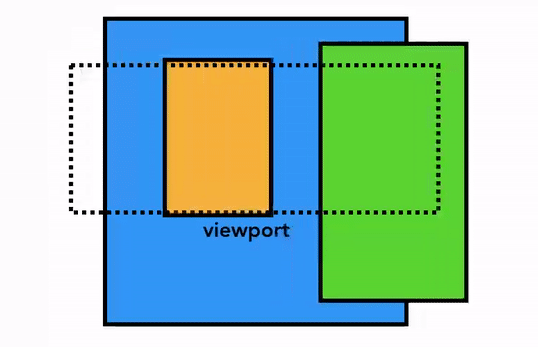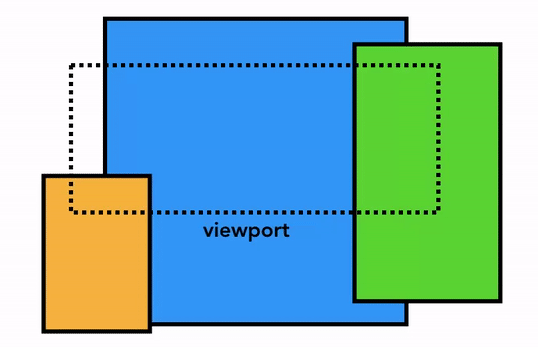
요소가 어떤 레이어에 존재해야 하는지를 알아내기 위해 메인 스레드는 레이아웃 트리를 이용하여 레이어 트리(layer tree)를 만들어 냅니다. <video>, <canvas> 요소 및 CSS의 opacity, 3D transform 속성 등은 새로운 레이어를 생성하도록 합니다. 또한, 슬라이드 메뉴와 같이 페이지의 특정 부분을 다른 레이어로 분리하고 싶다면 CSS의 will-change 속성을 이용하여 별도의 레이어로 구성되게끔 할 수 있습니다. 이외에도 레이어를 생성하도록 하는 것들은 여기서 보실 수 있습니다.
일반적으로, 레이어를 이용하면 GPU를 사용하여 그리기 때문에 성능이 향상될 수 있습니다. 하지만 무턱대고 will-change 같은 속성을 남발하여 레이어를 과도하게 많이 만들게 되면 오히려 합성하는데 시간이 더 걸리게될 수도 있고, 메모리 낭비가 발생할 수도 있으므로 반드시 성능을 먼저 측정한 다음 최적화를 수행해야만 합니다.
이렇게 레이어 트리가 만들어지고 페인트 순서가 결정되면 브라우저의 메인 스레드는 이러한 정보들을 합성 스레드(compositor thread)로 넘깁니다. 그리고 이러한 정보들을 넘겨받은 합성 스레드는 각 레이어를 래스터화 하기 시작합니다. 어떤 레이어는 그 크기가 전체 페이지 길이만큼 길 수도 있기 때문에 합성 스레드는 레이어를 타일(tile)로 나눈 다음 각 타일들을 래스터 스레드로 넘깁니다. 그럼 래스터 스레드는 각 타일을 래스터화 하고 이들을 GPU 메모리에 저장합니다:
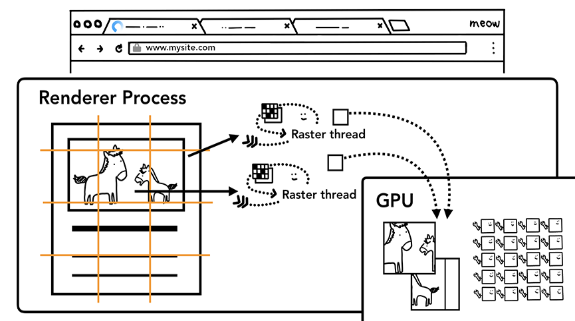
| 💡 |
|---|
| 래스터화 작업 역시 GPU의 도움을 받기 좋은 단계 입니다. 이와 관련한 더 자세한 내용은 Software vs. GPU Rasterization in Chromium을 참고하세요. |
| 💡 |
|---|
| 합성 스레드 내부에도 레이어 트리가 여러 개 있습니다. 메인 스레드가 넘긴 레이어 트리는 합성 스레드의 대기 트리(pending tree)로 복사됩니다. 대기 트리는 최신 프레임을 나타내지만, 아직 화면에는 그려지지 않은 상태입니다. 현재 화면에 그려지고 있는 이전 프레임은 활성 트리(active tree)로 그린 프레임입니다. 최신 정보로 화면을 갱신할 때는 대기 트리와 활성 트리를 스왑합니다. 이와 관련한 더 자세한 내용은 Native One-copy Texture Uploads for Chrome OS…를 참고하세요. |
이때 합성 스레드는 래스터 스레드의 우선순위를 조정할 수 있는데, 이렇게 해서 뷰포트(혹은 뷰포트 근처)에 있는 요소들이 먼저 래스터화될 수 있도록 할 수 있습니다. 또한 각 레이어는 화면을 줌-인 했을때를 대비해 화소(resolution)가 다른 여러 개의 타일을 준비합니다.
이렇게 타일을 래스터화하고 나면 합성 스레드는 draw quads라고 하는 타일들의 정보를 모아서 합성 프레임(compositor frame)을 만듭니다:
- Draw quads: 메모리상에서의 타일의 위치 및 페이지를 합성할 때 타일을 페이지의 어디에 그려야 할 지와 같은 정보들을 담고 있습니다.
- 합성 프레임: draw quads의 모음으로, 어떤 페이지의 한 프레임을 나타냅니다.
여기까지 했으면 합성 프레임은 IPC를 통해 브라우저 프로세스로 전달됩니다. 이때 브라우저 UI의 변화 등으로 인해 또 다른 합성 프레임이 추가될 수 있습니다.
이렇게 브라우저 프로세스로 전달된 합성 프레임들은 화면에 표시되기 위해 GPU로 전달됩니다. 만약 유저가 화면을 스크롤하는 경우 합성 스레드는 새로운 합성 프레임을 만들어 GPU로 보냅니다:
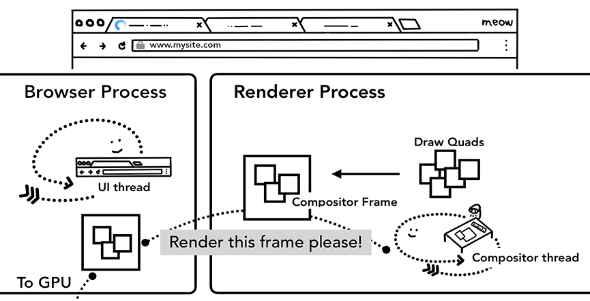
| 💡 |
|---|
| 2019년 4월 기준으로, 앞으로는 브라우저 프로세스를 거치지 않고 합성 프레임을 곧장 GPU 프로세스로 보낼 예정이라고 합니다. |
렌더링 파이프라인을 업데이트 하는 것은 비싼(costly) 작업입니다.
이렇게 살펴본 렌더링 파이프라인에서 중요한 점은 각 단계의 결과가 다음 단계에서 새로운 데이터를 생성하는 데에 사용된다는 것입니다. 즉, 앞 단계의 출력이 뒷 단계의 입력이 되는 것이죠.
예를 들어 레이아웃 트리에서 무언가 변경되면 여기에 영향을 받은 부분의 페인트 순서 또한 다시 계산되어야 합니다:
만약 어떤 요소에 애니메이션을 적용한 경우, 브라우저는 애니메이션과 관련된 작업을 매 프레임 사이마다 수행해야만 합니다. 대부분의 디스플레이들은 60fps(즉, 화면을 1초에 60번 리프레쉬 함)이므로 이러한 작업을 약 16.66ms 마다 해야한다는 뜻이죠. 이렇게 매 프레임(초당 60개의 프레임)마다 요소들을 움직인다면 사용자의 눈에는 부드럽게 움직이는 것처럼 보일 것입니다. 하지만 만약 몇몇 프레임을 빠트리게 되면 페이지는 “버벅(janky)“이는 것처럼 보일 것입니다:
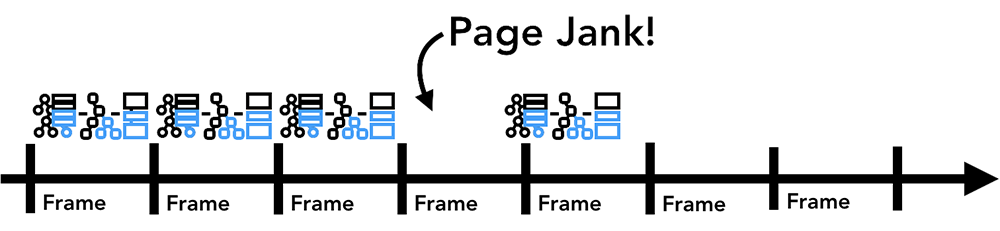
렌더링 작업이 화면 주사율에 잘 맞춰 진행되고 있다고 하더라도, 이러한 계산들은 메인 스레드에서 동작하기 때문에 만약 애플리케이션이 다른 자바스크립트 작업을 수행한다면 이로 인해 렌더링 작업을 처리하지 못해 화면이 버벅대는 것처럼 보일 수도 있습니다:
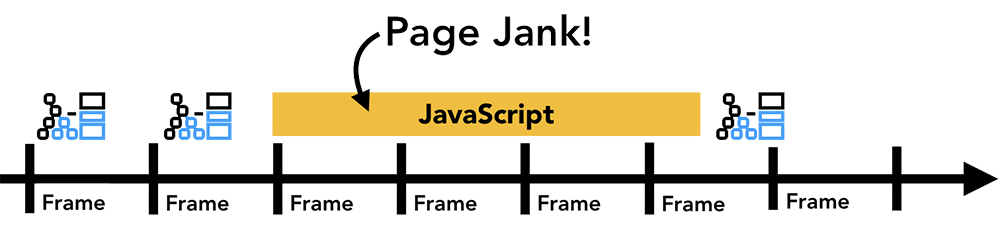
따라서 이러한 상황을 방지하기 위해 requestAnimationFrame을 사용하여 계산이 오래 걸리는 작업들을 작은 조각(chunk)들로 나눠서 매 프레임 마다 실행하도록 할 수 있습니다. 혹은 Web Worker를 이용하여 메인 스레드 차단을 방지할 수도 있고요:
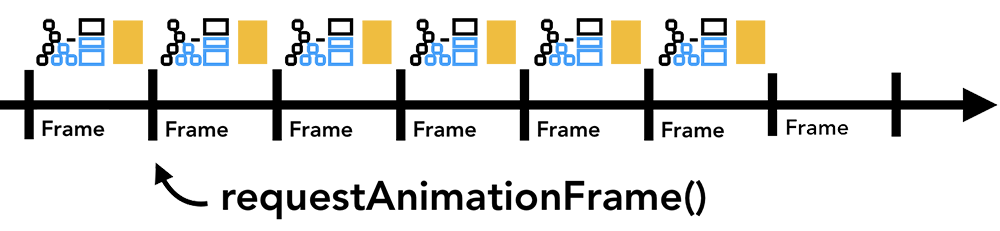
이와 관련된 주제는 여기서 더 많이 살펴보실 수 있습니다.
레퍼런스
- https://dev.to/gitpaulo/journey-of-a-web-page-how-browsers-work-10co
- https://www.html5rocks.com/en/tutorials/internals/howbrowserswork/#CSS_parsing
- https://medium.com/jspoint/how-the-browser-renders-a-web-page-dom-cssom-and-rendering-df10531c9969
- https://developers.google.com/web/updates/2018/09/inside-browser-part3
- https://developers.google.com/web/fundamentals/performance/critical-rendering-path
- https://developer.mozilla.org/en-US/docs/Web/Performance/How_browsers_work
- https://www.html5rocks.com/en/tutorials/speed/layers/
- Analyzing Critical Rendering Path Performance