인터럽트란?
카테고리: OSMarch 12, 2021
인터럽트란 무엇인가
인터럽트(interrupt)란, (주로 입/출력)하드웨어 장치의 처리, 혹은 예외 상황의 처리가 필요할 때 CPU에게 알려 이를 처리할 수 있도록 하는 일종의 신호입니다. 인터럽트는 여러 목적으로 사용될 수 있으며, 운영 체제와 하드웨어 간의 상호작용에 핵심적인 역할을 합니다. CPU에 인터럽트 신호가 들어오면, CPU는 현재 수행 중인 작업을 멈추고 즉시 인터럽트를 처리하기 위한 루틴(ISR, interrupt service routine)이 있는 곳으로 제어권을 넘겨 해당 인터럽트를 처리합니다. 이후 처리가 완료되면 CPU는 원래 수행하고 있던 동작을 재개합니다.
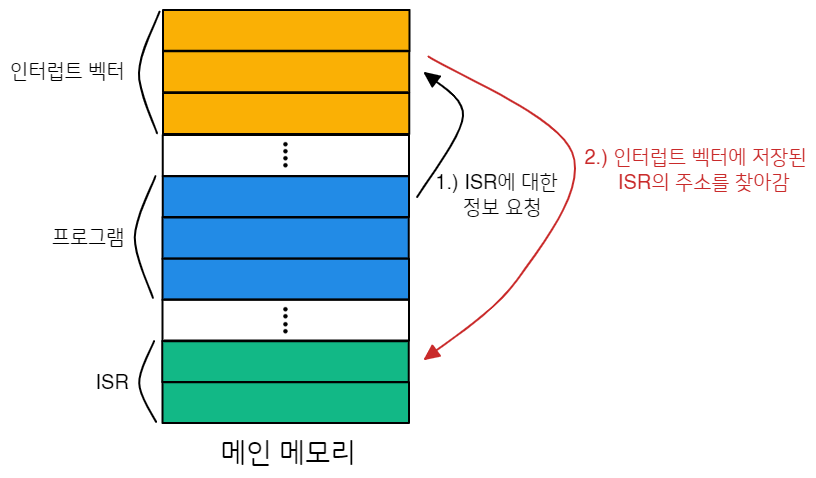
각 컴퓨터 시스템마다 고유의 인터럽트 메커니즘이 있지만, 몇몇 공통적인 특성들이 존재합니다. 인터럽트가 발생하면 반드시 제어권을 적절한 ISR에게 넘겨야 합니다. 일반적으로 ISR을 가리키는 포인터 테이블(배열)을 사용하여 인터럽트를 빠르게 처리하는데, 보통 이 포인터 테이블은 메모리의 낮은 주소에 위치합니다.
이처럼 ISR들의 주소에 대한 배열(테이블)을 인터럽트 벡터(interrupt vector)라고 하는데, 인터럽트 벡터는 인터럽트 요청에 포함된 고유 숫자(id)로 해당 인터럽트를 인덱싱하여 이 인터럽트를 처리하는 ISR의 주소를 제공합니다. 윈도우와 UNIX 운영 체제들은 이러한 방식으로 인터럽트를 처리합니다:
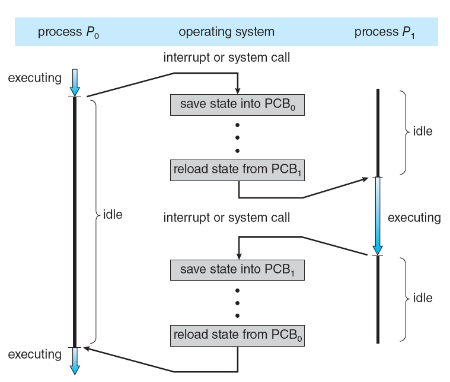
이후 인터럽트 처리가 끝나면 원래 수행하던 상태로 되돌아와야 하므로 인터럽트가 발생한 당시의 상태를 반드시 어딘가에 저장해야만 합니다. 프로세스의 상태를 컨텍스트(context) 라고 하는데, 컨텍스트는 PCB(Process Control Block)에 저장됩니다. 이렇게 프로세스의 상태를 저장함으로써, 인터럽트를 처리하고 나면 다시 원래 상태로 돌아와서 마치 아무일도 일어나지 않은 것 처럼 기존의 동작을 이어서 수행할 수 있습니다.
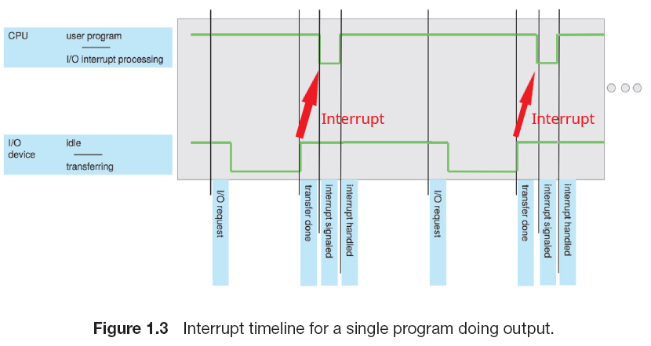
위 내용을 바탕으로 좀 더 자세히 살펴봅시다. 일반적으로 I/O장치와 같은 대부분의 외부 장치들은 CPU보다 훨씬 느린데, 예를 들어 CPU가 프린터와 데이터를 주고받는 경우 매번 쓰기 동작을 수행할 때마다 CPU는 프린터가 작업을 마칠 때까지 기다려야 할 것입니다. 다음 그림에 이와 같은 상황이 묘사되어 있습니다:
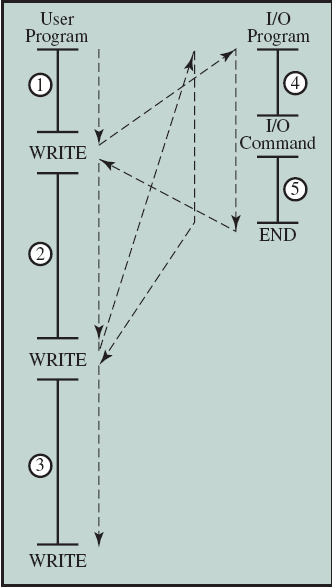
그림의 1, 2, 3번은 I/O 동작을 하지 않는 유저 프로그램을 나타내고, 4번은 I/O와 관련된 프로그램 (실제 I/O 수행을 위한 사전 작업 등), 5번은 I/O 동작을 완료하는 (I/O 동작을 성공적으로 수행했는지, 실패했는지 등에 대한 flag 설정과 같은 동작을 수행) 것을 나타냅니다. 이때 I/O 장치가 실제로 I/O 동작을 수행하는 단계는 4번과 5번 사이입니다. 만약 인터럽트를 사용하지 않는다면, 프로세서는 4번을 실행한 후 장치가 동작을 끝마칠 때까지 기다려야 합니다. 이후 장치가 동작을 끝마치면 5번을 실행하고, 다시 유저 프로그램으로 넘어오게 됩니다. 생각해보면 엄청 비효율적이죠?
똑같은 상황에 대해 인터럽트를 사용하는 경우를 살펴봅시다:
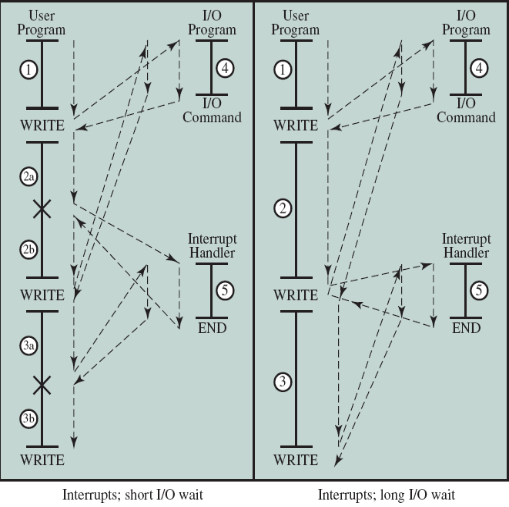
위 그림에서 볼 수 있듯이, 인터럽트를 이용하면 프로세서는 I/O 장치가 작업을 수행하는 도중에 다른 명령을 수행할 수 있습니다. 좀 더 자세히 살펴보자면, 유저 프로그램에서 WRITE 시스템 콜을 발생시켜 4번에서 I/O장치로 하여금 I/O를 수행할 준비를 시키고 실제 I/O 동작을 하도록 합니다. 그러고 나면 제어권이 다시 유저프로그램으로 돌아와 명령을 실행하다가 (동시에 I/O 장치가 데이터를 쓰는 중입니다), I/O 동작이 완료되면 인터럽트에 의해 인터럽트 핸들러로 제어권을 넘겨 I/O 관련 처리를 하고(5번), 처리가 완료되면 다시 원래 상태로 돌아와 하던 작업을 이어서 수행합니다.
이처럼 인터럽트를 사용하면 CPU를 놀게 놔두지 않고 사용할 수 있으므로 성능을 향상할 수 있습니다. 여기서 왼쪽 상황과 오른쪽 상황의 차이점은 왼쪽 상황의 경우, I/O를 수행하는 시간이 상대적으로 짧아서 유저 프로그램을 실행하는 도중에 인터럽트가 발생하는 상황이고, 오른쪽 상황의 경우 I/O를 수행하는 시간이 상대적으로 길어 먼저 발생한 I/O의 수행이 채 끝나기도 전에 두 번째 I/O 요청이 발생하는 경우입니다. 이 경우, 먼저 발생한 I/O의 처리가 완료될 때까지 기다려야 합니다.
구현
기본적인 인터럽트 메커니즘은 다음과 같습니다. 우선 CPU에는 인터럽트 요청 라인(interrupt-request line)이라는 전선(wire)이 존재하는데, CPU는 매번 하나의 명령을 실행한 후 인터럽트 요청 라인을 확인하여 인터럽트가 들어왔는지를 확인합니다. 만약 인터럽트 요청 라인에 인터럽트 신호가 들어온 것을 확인하면 해당 인터럽트의 인터럽트 번호(interrupt number)를 읽은 뒤, 인터럽트 벡터에서 해당 명령에 대응되는 ISR로 이동한 후 ISR을 실행합니다.
이때 인터럽트 핸들러(즉, ISR)는 인터럽트 처리 도중 변경될 수 있는 모든 상태를 저장한 뒤 인터럽트 발생 원인을 살펴본 후 그에 맞는 적절한 동작을 수행하고 return_from_interrupt와 같은 명령을 실행시켜 인터럽트가 발생하기 전의 원래 상태로 되돌아갑니다.
즉, 장치 컨트롤러(혹은 프로세스)가 인터럽트를 발생(raise) 시키고, CPU가 감지(catch)해서 인터럽트를 적절한 인터럽트 핸들러에게 할당(dispatch)하면 해당 핸들러가 인터럽트를 처리합니다. 아래 그림에 인터럽트 기반 I/O 사이클에 관한 내용이 묘사되어 있습니다:
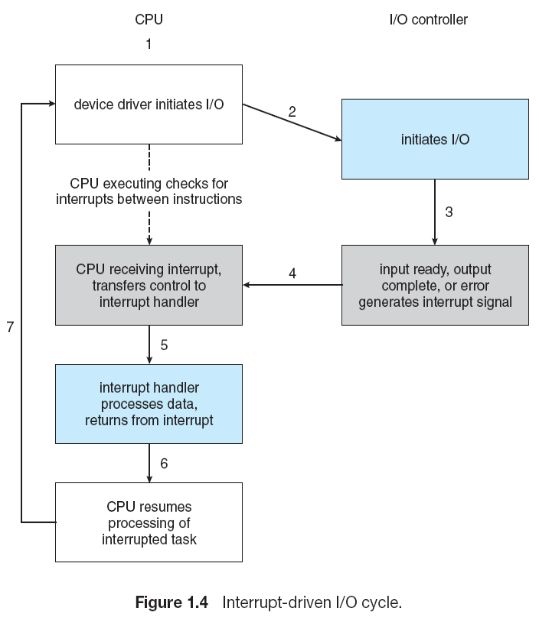
위와 같은 인터럽트 메커니즘을 통해, CPU는 이벤트를 비동기적으로 처리할 수 있습니다. 하지만 현대 운영 체제에서는 좀 더 정교한 인터럽트 처리 방식이 필요합니다:
- 중요한 명령을 수행하는 동안에는 인터럽트 처리를 잠시 미룰 필요가 있습니다.
- 장치에 관한 적절한 인터럽트 핸들러를 할당 하는데 효율적인 방법이 필요합니다.
- 운영 체제가 우선순위를 고려하여 인터럽트를 처리할 수 있게끔 다중 레벨 인터럽트가 필요합니다.
현대 컴퓨터 하드웨어에서, 이러한 세 가지 특성들은 CPU와 인터럽트 제어 하드웨어(interrupt-controller hardware)를 통해 처리할 수 있습니다. 대부분의 CPU는 두 개의 인터럽트 요청 라인을 가지고 있는데, 각각 다음과 같은 인터럽트를 위한 라인입니다:
- Non-Maskable Interrupt: 반드시 지금 처리해야하는 (무시할 수 없는) 인터럽트로, 회복할 수 없는(unrecoverable) 메모리 에러와 같은 이벤트를 처리할 때 사용됩니다.
- Maskable Interrupt: 도중에 인터럽트 되어서는 안 되는 중요한 명령 처리를 위해 인터럽트 처리를 잠시 중단하거나 무시할 수 있는 인터럽트로, 주로 장치 컨트롤러가 서비스를 요청할 때 사용됩니다.
앞서 살펴본 인터럽트 벡터의 존재 이유를 복기해봅시다. 하나의 일반적인 인터럽트 핸들러(generic handler)를 통해 처리한다면 인터럽트가 발생했을 때 어떤 인터럽트 처리가 필요한지 판단하기 위해 가능한 모든 인터럽트 소스를 찾아야 할 것입니다. 이는 비효율적이므로, 인터럽트 벡터와 같이 ISR들의 주소를 저장하는 테이블을 통해 인터럽트를 처리합니다.
하지만 실제로 컴퓨터들은 인터럽트 벡터가 보유한 주소보다 더 많은 장치를(즉, 인터럽트 핸들러를) 가지고 있습니다. 즉, 인터럽트 벡터에 모든 장치들의 ISR 주소를 저장할 수 없다는 뜻입니다. 이 문제를 해결할 수 있는 일반적인 방법은 각 인터럽트 벡터의 요소가 인터럽트 핸들러들이 저장된 리스트의 헤드를 가리키는 인터럽트 체이닝(interrupt chaining) 방식을 사용하는 것입니다. (즉, 해시 테이블 separate chaining의 방법과 유사하다고 볼 수 있습니다).
아래 그림은 인텔 프로세서에 대한 인터럽트 벡터를 나타낸 것입니다. 벡터 번호 0부터 31까지는 non-maskable 인터럽트, 32 부터 255까지는 maskable 인터럽트 입니다:
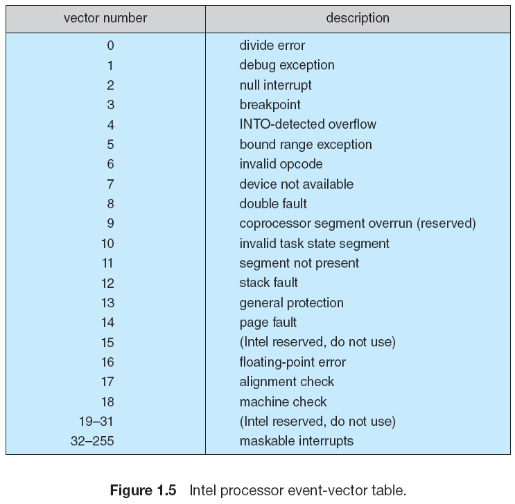
인터럽트 메커니즘은 또한 인터럽트 우선 순위 레벨(interrupt priority level)을 구성합니다. 이러한 우선순위 레벨을 통해, CPU는 우선순위가 높은 인터럽트 부터 처리하도록 동작합니다.
종류
주요 인터럽트는 다음과 같습니다:
| 타입 | 설명 |
|---|---|
| 프로그램 | arithmetic overflow, division by zero, illegal machine instruction, 허용된 메모리 공간 이외의 공간에 대한 접근 등에 의해 발생합니다. |
| 타이머 | 프로세서 안에 있는 타이머에 의해 발생합니다. 프로세서가 특정한 기능을 주기적으로 수행하도록 합니다. |
| 입/출력 | I/O 컨트롤러에 의해 발생하며, 주로 입/출력 동작의 완료, 프로세서로부터 요청받았을 때, 혹은 (다양한) 에러에 의해 발생합니다. |
| 하드웨어 failure | 전원(power) failure, 혹은 메모리 parity 에러 등에 의해 발생합니다. |
인터럽트는 크게 하드웨어 인터럽트, 소프트웨어 인터럽트로 나눌 수 있습니다.
하드웨어 인터럽트(외부 인터럽트)
하드웨어 인터럽트는 CPU 혹은 기타 외부 장치들이 자신에게 발생한 사건을 운영 체제에 알리는 메커니즘으로, 비동기식 이벤트입니다. 하드웨어 인터럽트에는 다음과 같은 종류가 있습니다:
- 전원 공급 오류
- CPU 또는 기타 하드웨어 장치 오류
- 타이머 인터럽트
- I/O
소프트웨어 인터럽트(내부 인터럽트, 트랩)
소프트웨어 인터럽트는 현재 실행 중인 프로세스에서 발생한 소프트웨어적인 사건을 운영 체제에 알리는 메커니즘으로, 동기식 이벤트입니다. 소프트웨어 인터럽트에는 다음과 같은 종류가 있습니다:
- 시스템 콜
- 0으로 나누기
- 존재하지 않는 메모리 주소에 접근
- 오버플로우
- page fault
여러개의 인터럽트
여태껏 하나의 인터럽트만 발생하는 경우를 살펴보았는데, 만약 여러 개의 인터럽트가 발생하면 어떻게 될까요? 예를 들어, 네트워크를 통해 데이터를 받아서 결과를 프린터에 출력하는 프로그램이 있다고 해봅시다. 프린터는 결과를 출력할 때마다 인터럽트를 발생시킬 것입니다. 또한, 네트워크 컨트롤러는 데이터가 도착할 때마다 인터럽트를 발생시킬 것인데, 이때 데이터는 하나의 문자일 수도 있고, 블록 단위일 수도 있을 테지요.
이 상황에서, 프린터 인터럽트가 처리되는 도중에 네트워크 인터럽트가 발생한다면 어떻게 될까요? 이 경우 여러 개의 인터럽트를 처리하기 위해 두 가지 방법이 사용될 수 있는데, 우선 첫 번째는 어떤 한 인터럽트가 처리되는 동안은 다른 인터럽트의 발생을 중지시키는 것입니다. 즉, 프로세서가 인터럽트 신호를 (일단) 무시한다는 뜻입니다. 어떤 한 인터럽트가 처리되는 동안 발생한 다른 인터럽트는 일반적으로 대기(pending) 상태가 되어 이후에 프로세서가 인터럽트 발생을 다시 허용했을 때 처리됩니다.
이 방법은 인터럽트가 발생한 순서대로 처리된다는 점에선 좋은 방법이지만, (우선순위가 높은) 빨리 처리되어야 하는 요구를 고려하지 못한다는 단점이 있습니다. 예를 들어, 네트워크로부터 어떤 데이터가 도착했을 때 발생한 인터럽트는 (앞으로 도착할) 또 다른 데이터들을 위해 즉시 처리되어야 할 필요가 있습니다. 만약 두 번째 데이터가 도착하기 전에 첫 번째 데이터가 처리되지 못한다면, 데이터가 소실될 가능성이 있지요.
두 번째 방법은 인터럽트 간에 우선순위를 매겨 처리하는 방법입니다. 예를 들어 프린터, 디스크, 네트워크로 구성된 시스템을 생각해봅시다. 이때 각 장치들의 우선순위는 각각 2, 4, 5입니다:
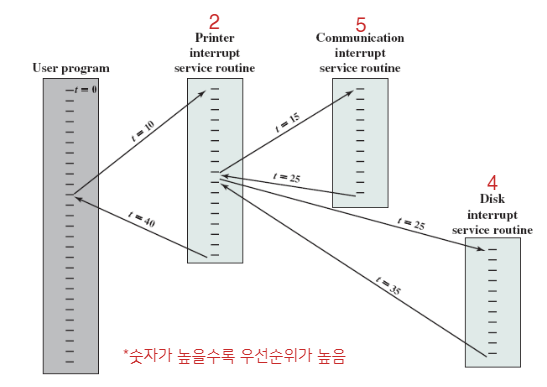
우선, t = 0 에 유저 프로그램이 시작됩니다. t = 10에 프린터 인터럽트가 발생하여 유저 프로그램의 정보가 시스템 스택에 저장되고, 프로그램의 흐름이 프린터의 ISR로 넘어갑니다. 이 ISR이 실행되는 도중, t = 15에 네트워크 인터럽트가 발생합니다. 네트워크의 우선순위(5)가 프린트(2)보다 높기 때문에 인터럽트가 수락되어 처리됩니다. 이번에는 프린터의 상태가 스택에 저장되고, 프로그램의 흐름이 네트워크 인터럽트의 ISR로 넘어갑니다. 이 루틴을 실행하는 도중, t = 20에 디스크 인터럽트가 발생하는데 디스크의 우선순위(4)가 네트워크(5)보다 낮기 때문에 디스크 인터럽트는 대기 상태가 되고 계속해서 네트워크 ISR이 실행됩니다.
이후 t = 25가 되어 네트워크 ISR이 종료되면 프로그램의 흐름이 프로세서의 이전 상태 (프린터 ISR)로 다시 넘어갑니다. 이때 프린터 ISR이 실행되기 전에, 대기 하고있던 디스크 인터럽트가 수락되어 프로그램의 흐름이 디스크 ISR로 넘어가게 됩니다 (디스크의 우선순위가 프린터보다 높으므로). 그리고 나서 t = 35에 디스크 ISR이 끝나야지만 프린터 ISR의 실행이 재개되고, t = 40에 프린터 ISR도 종료가 되면 프로그램 흐름이 최종적으로 다시 유저 프로그램으로 넘어가서 모든 인터럽트가 처리되게 됩니다.