구글 V8 엔진 살펴보기
카테고리: JavaScriptMay 21, 2022
이 포스트에선 자바스크립트를 해석하여 실행하는 구글 V8 엔진을 살펴보겠습니다.
V8 엔진은 대표적으로 구글 크롬 브라우저, Node.js 에서 사용되는 자바스크립트 엔진으로 C++로 작성되었으며, 오픈소스이므로 V8엔진의 코드를 여기서 보실 수 있습니다.
동작 원리
우선, V8 엔진의 구조는 아래 그림과 같이 나타낼 수 있습니다:
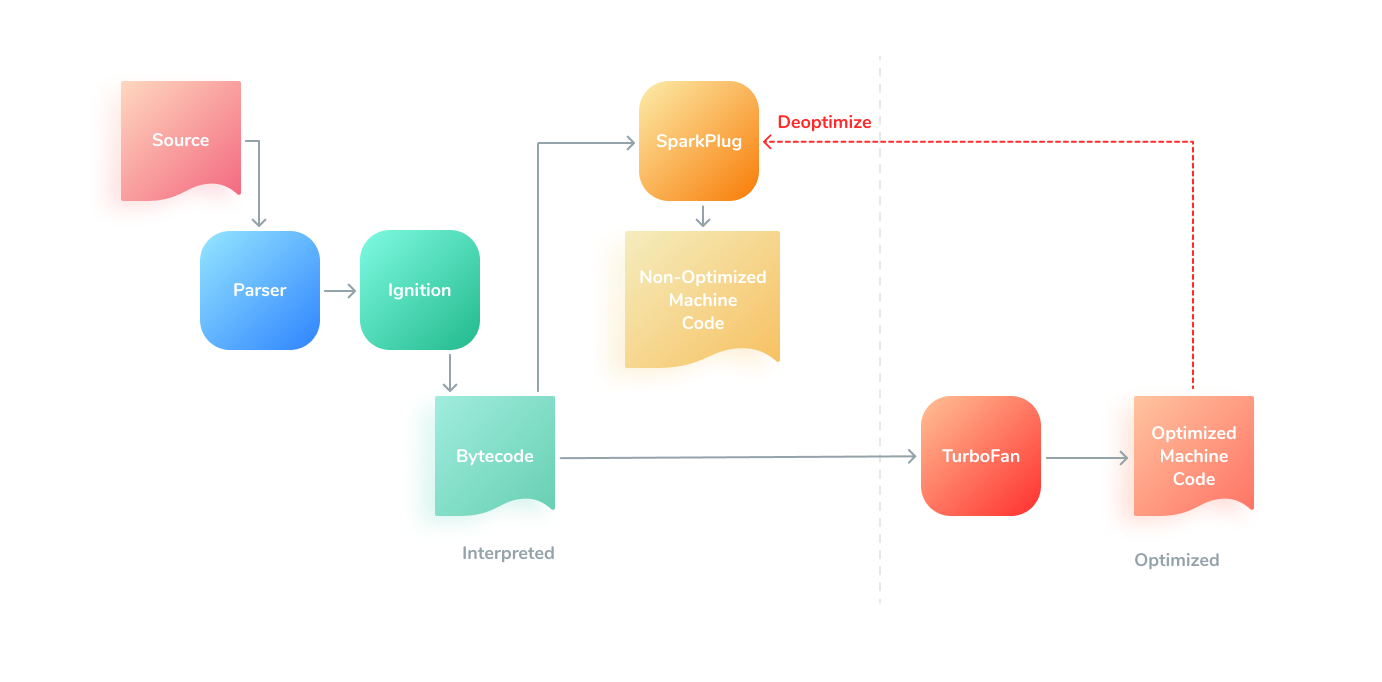
우선, V8 엔진은 자바스크립트 소스 코드를 파서(parser)에게 넘기는데, 파서는 자바스크립트 코드를 분석하여 추상 구문 트리(Abstract Syntax Tree, AST)와 스코프를 생성합니다. 그러면 인터프리터(Interpreter)는 AST를 기반으로 바이트 코드(Bytecode)를 생성하고, 이후 이 바이트 코드를 실행함으로써 실제 자바스크립트가 실행됩니다. 이때, 자주 사용되는 코드(hot한 코드라고도 합니다)는 최적화 컴파일러로 컴파일하여 기존의 바이트 코드보다 더 최적화된 기계어로 실행되며, 특정 상황이 발생하면 적용된 최적화가 해제(de-optimize)되어 최적화되지 않은 코드로 실행되기도 합니다.
이 과정을 하나씩 살펴보겠습니다.
파싱
파싱이란 소스 코드를 추상 구문 트리(AST)로 변환하는 과정입니다. 이때 AST는 컴파일러에서 널리 사용되는 자료구조로서, 쉽게 말해 소스 코드의 문법적 구조를 나타낸 것이라고 할 수 있습니다.
아래 예시 코드에 대한 AST를 그림으로 나타내면 아래와 같습니다:
function fn() {
let a = 0;
if (a === 0) {
let b = 'foo';
return a;
}
}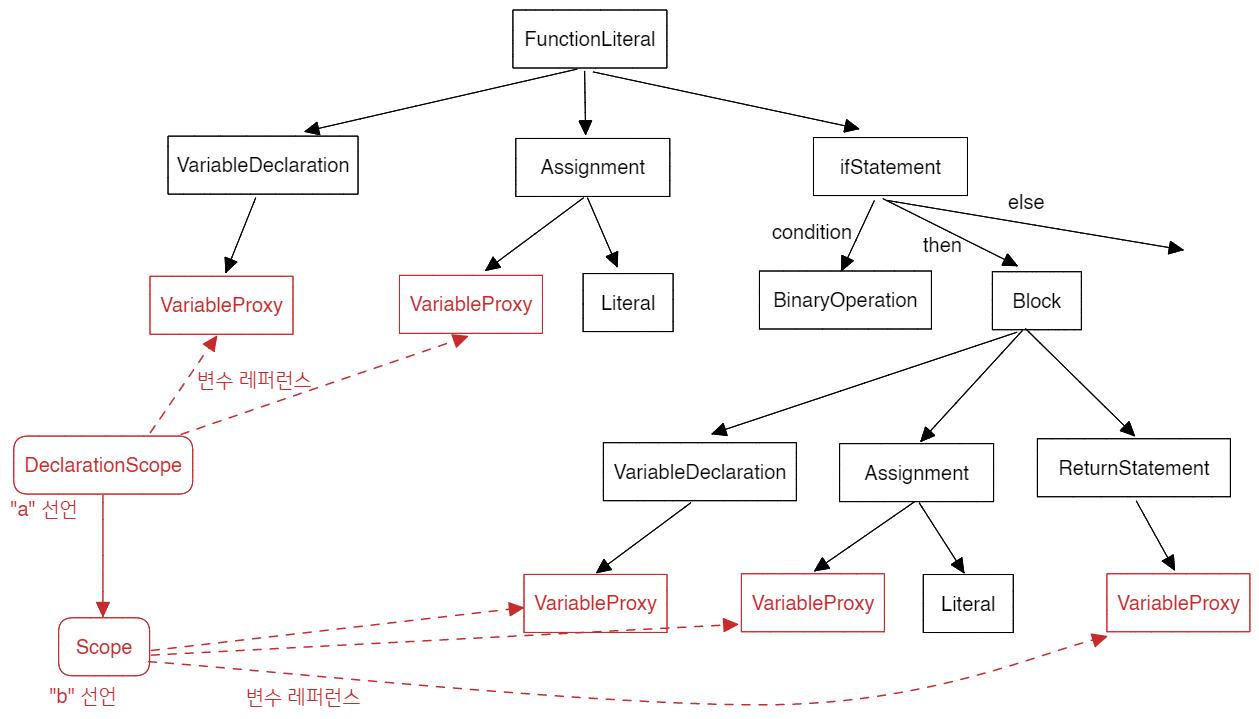
위 그림과 같이, 파싱은 소스 코드를 분석하여 컴퓨터가 이해하기 쉬운 형태의 구조로 변환하는 과정이라고 할 수 있습니다.
아래 그림에서 볼 수 있듯, 파싱 작업은 V8 엔진 전체 실행 시간의 약 15~20%를 차지하는 작업입니다:
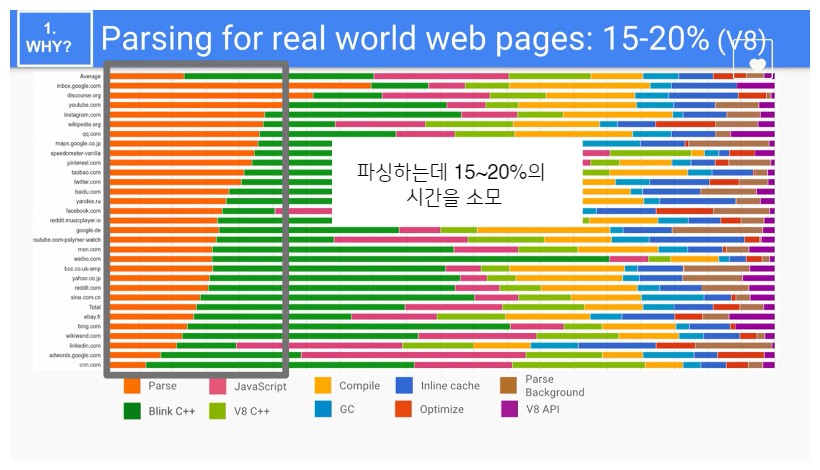
따라서 파싱에 소요되는 시간을 줄여 자바스크립트 실행 속도를 높이기 위해 V8은 크게 parser와 pre-parser 두 가지 파서를 사용합니다.
-
parser(eager 파서라고도 합니다):- 지금 실행하는데 필요한 구문들을 파싱합니다.
- AST를 만듭니다.
- 스코프를 생성합니다.
- 모든 syntax 에러를 찾아냅니다.
-
pre-parser(lazy 파서라고도 합니다):- 이후에 사용될 코드를 파싱하는 데 사용됩니다.
- AST를 만들지 않습니다.
- 스코프를 만들긴 하지만 스코프에 변수 선언 및 변수 레퍼런스를 넣지는 않습니다.
parser에 비해 약 두 배가량 빠릅니다.- 몇몇 에러만 찾아냅니다.
parser에 의해 파싱되는 코드의 예:
// top-level 코드는 항상 eager 파싱
let a = 0;
// IIFE는 즉시 실행되어야 하므로 eager 파싱
(function IIFE() {})();
// IIFE가 아닌 top-level 함수는 현재 실행되지 않으므로 lazy 파싱
function lazy() {}
// 하지만 이후에 해당 함수가 실행되는 경우 eager 파싱
lazy();파싱에 관한 것은 자바스크립트 스펙에 존재하지 않기 때문에 브라우저마다 파싱을 구현한 방식이 다를 수 있습니다. V8의 경우 자바스크립트 문법에 기반하여 해당 코드를 eager 파싱할지 lazy 파싱할지 추측해서 파싱 작업을 수행합니다.
바이트 코드 생성
파싱 단계를 통해 AST가 생성되면, V8 엔진의 Ignition 인터프리터는 이를 기반으로 바이트 코드를 생성합니다. 이때 바이트 코드란 기계어(machine code)를 추상화한 코드라고 할 수 있습니다.
사실 V8 버전 5.9 이전에선 Full-codegen 이라는 것을 통해 전체 코드를 한 번에 컴파일하는 방식을 사용했었는데, 이 방식은 메모리를 너무 많이 잡아먹는다는 단점이 있었습니다 (모바일 크롬 M53 버전을 기준으로, Ignition을 사용했을 때보다 Full-codegen을 사용했을 때보다 9배가량의 메모리를 더 소모했다고 합니다). 또한 자바스크립트는 동적 타이핑 언어라서 소스 코드가 실행되기 전에는 알 수 없는 값들이 많았기 때문에 최적화를 수행하기도 어려웠다고 합니다.
바이트 코드가 실제 물리적인 CPU 모델과 흡사하게 구성되어 있다면 바이트 코드를 기계어로 컴파일하는 것이 쉬워집니다. 이로 인해 인터프리터를 레지스터(혹은 스택)머신이라고도 부르는데요, Ignition은 누산기 레지스터(accumulator register)를 사용하는 레지스터 머신이라고 할 수 있습니다.
V8에는 수백 개의 바이트 코드가 존재하는데, 과연 어떻게 생겼는지를 간략히 살펴보겠습니다. 모든 바이트 코드는 여기에서 보실 수 있습니다.
각 바이트 코드는 입·출력을 레지스터의 operand로 표현합니다. 대부분의 바이트 코드는 누산기 레지스터를 사용하는데 (바이트 코드가 이를 명시하지는 않습니다), 예를 들어 Add r1 바이트 코드는 레지스터 r1의 값을 accumulator 레지스터에 더한다는 뜻입니다. 이러한 방식을 통해 바이트 코드의 길이가 짧아지고, 메모리를 절약할 수 있습니다.
대부분의 바이트 코드는 Lda 혹은 Sta로 시작하는데, 여기 있는 a는 accumulator 레지스터를 나타냅니다. 예를 들어, LdaSmi [42]는 Smi(Small integer) 42를 accumulator 레지스터에 로드하는 것을 의미합니다. 또, Star r0는 현재 accumulator에 있는 값을 r0 레지스터에 저장하는 것을 의미합니다.
아래의 예시 코드를 살펴봅시다:
function incrementX(obj) {
return 1 + obj.x;
}
incrementX({ x: 42 });이때, Node.js(버전 8.3 이상)를 통해 바이트 코드를 실행할 때 --print-bytecode 옵션을 주면 바이트 코드를 출력할 수 있습니다.
$ node --print-bytecode incrementX.js
...
[generating bytecode for function: incrementX]
Parameter count 2
Frame size 8
12 E> 0x2ddf8802cf6e @ StackCheck
19 S> 0x2ddf8802cf6f @ LdaSmi [1]
0x2ddf8802cf71 @ Star r0
34 E> 0x2ddf8802cf73 @ LdaNamedProperty a0, [0], [4]
28 E> 0x2ddf8802cf77 @ Add r0, [6]
36 S> 0x2ddf8802cf7a @ Return
Constant pool (size = 1)
0x2ddf8802cf21: [FixedArray] in OldSpace
- map = 0x2ddfb2d02309 <Map(HOLEY_ELEMENTS)>
- length: 1
0: 0x2ddf8db91611 <String[1]: x>
Handler Table (size = 16)이를 하나씩 살펴봅시다:
StackCheck
StackCheck 는 스택 포인터의 상한값을 확인하는 작업인데, 만약 스택이 임계값을 넘은 경우 스택 오버플로우가 발생할 수 있으니 함수 실행을 중단해버립니다.
LdaSmi [1]
LdaSmi [1]는 small integer 1을 accumulator 레지스터에 로드하라는 뜻입니다:
![LdaSmi [1]](https://cdn.jsdelivr.net/gh/jaehyeon48/jaehyeon48.github.io@master/assets/images/javascript/google-v8-engine/ldasmi1.png)
Star r0
Star r0는 현재 accumulator 레지스터에 있는 값을 r0 레지스터에 저장하라는 뜻입니다:
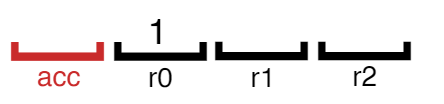
LdaNamedProperty a0, [0], [4]
우선 하나씩 살펴보겠습니다. LdaNamedProperty a0, [0], [4] 에서 LdaNamedProperty a0, [0] 는 이름이 붙은(named) 프로퍼티를 accumulator 레지스터에 로드하라는 뜻입니다. 이때 ai 에서 i 는 함수(여기선 incrementX())의 i 번째 인자를 의미합니다 (0-based 인덱스).
프로퍼티의 이름은 별도의 테이블을 통해 찾는데, a0 뒤에 오는 상수를 인덱스로 사용하여 찾습니다. 여기서 살펴보고 있는 LdaNamedProperty a0, [0], [4]의 경우 상수의 값이 [0] 이므로 별도의 테이블에서 0 번째 인덱스에 해당하는 이름을 사용하게 되는 것이죠:
- length: 1
0: 0x2ddf8db91611 <String[1]: x>여기선 테이블의 0 번째 인덱스에 대응되는 이름이 x 이므로 바이트 코드 LdaNamedProperty a0, [0], [4]는 결과적으로 첫 번째 인자로 받은 객체(a0에 해당)의 x 프로퍼티를 accumulator 레지스터에 로드하게 됩니다.
그럼 맨 뒤의 [4]가 의미하는 것은 무엇일까요? 이는 incrementX() 함수의 피드백 벡터(feedback vector)의 인덱스를 의미하는데, 피드백 벡터는 성능 최적화에 사용되는 정보들이 저장됩니다.
![LdaNamedProperty a0, [0], [4]](https://cdn.jsdelivr.net/gh/jaehyeon48/jaehyeon48.github.io@master/assets/images/javascript/google-v8-engine/ldanamedproperty.png)
Add r0, [6]
Add r0, [6]는 r0 레지스터에 있는 값을 accumulator 레지스터에 누적하라는 뜻입니다:
![Add r0, [6]](https://cdn.jsdelivr.net/gh/jaehyeon48/jaehyeon48.github.io@master/assets/images/javascript/google-v8-engine/addr06.png)
이때 [6]는 LdaNamedProperty a0, [0], [4] 와 마찬가지로 피드백 벡터의 인덱스를 나타내는 숫자입니다.
Return
Return 바이트 코드는 함수(여기선 incrementX())의 종료를 나타내는데, accumulator 레지스터에 저장된 값을 반환합니다. 그러면 해당 함수를 호출한 caller는 accumulator 레지스터에 저장된 값(43)을 가지고 이어서 작업을 해나갈 수 있게 되는 것이죠.
최적화 컴파일러
V8의 Ignition은 바이트 코드를 실행하면서 Profiler를 통해 어떤 함수가 자주 사용되는지, 어떤 타입이 사용되는지와 같은 정보들을 수집합니다. 그리고 이렇게 모인 profiling 데이터와 바이트 코드를 TurboFan에 넘겨 최적화된 기계어 코드를 생성합니다.
그럼 왜 Ignition(인터프리터)과 TurboFan(컴파일러)이 따로 존재하는 걸까요? 그 이유는, 일반적으로 인터프리터는 빠르게 바이트 코드를 생성할 수 있지만 대체로 바이트 코드는 그다지 효율적이지는 않습니다. 반대로 컴파일러는 기계어 코드를 생성하는 데 시간이 좀 걸리지만 훨씬 효율적이죠. 그래서 “비효율적인 코드일지라도 코드가 실행되는데 걸리는 시간을 줄일 것이냐 (인터프리터)” vs. “코드가 실행되는 데까지 시간이 좀 걸리더라도 효율적인 코드를 실행할 것이냐 (컴파일러)” 간의 trade-off를 고려한 것이라고 할 수 있습니다.
또한 최적화된 기계어 코드가 바이트 코드보다 일반적으로 메모리를 더 많이 사용하는데, 이러한 측면까지 모두 고려해서 자바스크립트 코드를 여러 개의 계층으로 나누어 실행하는 것입니다.

TurboFan이 사용하는 최적화 기법에는 대표적으로 히든 클래스(Hidden class), 인라인 캐싱(Inline caching) 등이 있습니다 (이에 관한 자세한 내용은 이 포스트를 참고해 주세요!). 간략하게 말하자면 히든 클래스는 비슷하게 생긴 객체들을 그룹화하는 것이고, 인라인 캐싱은 우리가 흔히 생각하는 캐싱과 같이 자주 사용되는 코드를 캐싱하는 기법입니다. 또한 앞서 말했듯이 TurboFan은 프로파일링 데이터를 기반으로 최적화를 진행하는데, 어떤 코드가 더 이상 최적화하기에 적합하지 않게 된다면(자바스크립트가 동적 타입 언어인 것과 연관이 있습니다) 이 코드에 대해 더 이상 최적화하지 않고 다시 원래의 바이트 코드로 돌아가서 바이트 코드를 실행합니다. 이를 de-optimizing 이라고 합니다.
비최적화 컴파일러
V8 버전 9.1, 크롬 버전 91부터 기존의 Ignition과 TurboFan의 중간 단계에 위치한 Sparkplug라는 비최적화 컴파일러가 도입되었습니다. 기존에 멀쩡히 잘 돌아가던 Ignition, TurboFan 이외에 Sparkplug라는 새로운 기술이 도입된 이유는 다음과 같다고 합니다:
기존의 Ignition과 TurboFan 사이에는 큰 성능 차이가 존재했습니다. 즉, 코드가 Ignition 인터프리터에 너무 오래 머무르면 최적화로 인한 성능 향상의 효과를 누릴 수 없고, 반대로 (적절하지 않은 시점에) TurboFan을 통해 너무 빨리 최적화를 해버리면 실제로 아직 “hot”하지 않은(즉, 그리 자주 사용되지는 않는) 함수들을 최적화해버리는 문제가 발생할 수 있고 심지어 미리 최적화한 코드를 이전으로 되돌려야 하는(de-optimize) 상황이 발생할 수 있습니다. 따라서 우리는 이러한 간극을 줄이고자 빠르고 심플한 비최적화 컴파일러를 도입하였는데, 이것이 바로 Sparkplug 입니다
Sparkplug는 AST가 아니라 Ignition이 생성한 바이트 코드를 기반으로 기계어 코드를 만들어내기 때문에 AST 분석 등의 작업을 수행할 필요가 없고, 또 TurboFan과는 다르게 별다른 최적화 작업을 수행하지 않기 때문에 빠르게 동작할 수 있다고 합니다. V8 개발팀에 따르면 Sparkplug를 도입함으로써 약 5~15%가량의 성능 향상이 있다고 합니다. 또, Sparkplug를 통해 CPU 점유율이 감소하여 모바일 기기 등에서 배터리 소모가 감소하는 효과가 있다고 합니다.
레퍼런스
- JavaScript Engines: The Good Parts™ - Mathias Bynens & Benedikt Meurer - JSConf EU 2018 - YouTube
- Franziska Hinkelmann: JavaScript engines - how do they even? | JSConf EU - YouTube
- Marja Hölttä: Parsing JavaScript - better lazy than eager? | JSConf EU 2017 - YouTube
- Understanding V8’s Bytecode. V8 is Google’s open source JavaScript… | by Franziska Hinkelmann | DailyJS | Medium
- 🚀⚙️ JavaScript Visualized: the JavaScript Engine - DEV Community
- V8 엔진은 어떻게 내 코드를 실행하는 걸까? | Evans Library
- Sparkplug — a non-optimizing JavaScript compiler · V8
- Sparkplug – V8 JavaScript baseline compiler | Medium
- V8 Gets a Non-Optimizing Compiler Stage to Improve Performance