유니코드와 Character Set에 관하여
카테고리: Computer ArchitectureJanuary 06, 2022
역사
옛날에 Unix가 개발되던 당시엔 오직 악센트가 없는 영문자만 잘 표현하면 됐었습니다. 이는 ASCII 코드를 사용해서 단 7비트만으로 표현할 수 있었는데, 예를 들어 대문자 A는 65, 소문자 a는 97과 같이 표현했습니다.

위 테이블에서 볼 수 있듯이, ASCII 코드는 32부터 127까지는 문자들을 표현하는데 사용했고 0부터 31까지는 컨트롤 문자를 나타내는데 사용했습니다. 이때 한 가지 문제가 생기는데, 이 당시 컴퓨터는 대부분 8비트 컴퓨터였기 때문에 7비트 짜리 ASCII 코드를 모두 사용하고도 나머지 1비트가 남았습니다. 그래서 사람들은 128부터 255까지의 코드를 각자 원하는대로 사용하기 시작했는데, 예를 들어 미국에서 사용된 컴퓨터에선 문자 코드 130이 é를 나타냈지만, 이스라엘에서 사용된 컴퓨터는 히브리어 ג를 나타냈습니다. 만약 미국인이 이력서 résumés를 보내면 이스라엘에선 rגsumגs라고 받았습니다.
결국 이러한 무질서함을 바로잡기 위해 ANSI 표준이 제정되었는데, 이 표준에서 문자 코드 128 밑으로는 ASCII와 동일하지만 128 이상의 코드에 코드 페이지라는 것을 정의해서 각 나라별로 다르게 사용하기로 했습니다. 예를 들어 이스라엘 컴퓨터는 코드 페이지 862번을, 그리스 컴퓨터는 737번을 사용했습니다.
한편 아시아에서 사용된 언어의 경우 수천 개의 문자가 존재하기 때문에 (당장 한국어만 봐도 가, 갸, 거, 겨, 고, … 등 총 11,172자가 존재합니다!) 8비트로는 어림도 없었습니다. 당시 이 문제는 흔히 DBCS (Double Byte Character Set)시스템, 즉 어떤 글자는 1바이트로 저장하고 어떤 글자는 2바이트로 저장하는 방식으로 해결하곤 했습니다.
하지만 사람들은 여전히 한 문자는 1바이트라고 인식하고 있었고, 다른 컴퓨터로 문자를 전송하거나 여러 나라 언어를 같이 사용하지 않는 이상 별문제가 없다고 생각했습니다. 하지만 잘 아시다시피, 인터넷이 발명된 이후 다른 컴퓨터로 문자를 전송하는 게 흔한 일이 되어버렸고 모든 것이 엉망진창이 되어버렸습니다. 하지만 다행스럽게도 유니코드가 개발되어 숨통이 트이게 되었습니다.
유니코드 (Unicode)
유니코드는 지구상에서 흔히 사용되는 언어 체계를 단 하나의 character set으로 표현하기 위해 개발된 시스템입니다. 흔히 유니코드는 16비트 문자 코드, 즉 하나의 문자를 16비트로 표현하는 시스템이므로 총 65,536개의 문자를 표현할 수 있다고 하는 경우가 있는데, 이는 사실이 아닙니다.
사실 유니코드에서 문자를 다루는 방식이 기존의 방식과 다르기 때문에, 유니코드를 이해하기 위해 유니코드 적인 방식(Unicode way)으로 생각하는 방법을 익히셔야 합니다.
이때까지 우리는 한 문자를 디스크나 메모리에 저장할 때 특정 비트에 매핑한다고 가정하였습니다:
A -> 0100 0001
하지만 유니코드에서 한 문자는 코드 포인트(code point)라는 것에 매핑됩니다. 그리고 이러한 코드 포인트를 메모리나 디스크에 어떻게 저장하느냐는 또 다른 이야기입니다.
유니코드에서 알파벳 A는 이데아입니다. 즉 하늘에 떠다니는, “본질”이라는 것이죠:
A
이 이데아 A는 B 혹은 a와는 다르지만 A, A, A와는 동일합니다. Times New Roman 폰트의 A는 Helvetica 폰트의 A와 똑같지만 소문자 a와는 다릅니다.
얼핏 보기엔 논란의 여지가 없는 사실인 것 같지만 몇몇 언어에서는 그렇지 않을 수 있습니다. 독일어 ß는 실제 문자일까요? 아니면 단순히 “ss”를 멋지게 쓰는 방식일까요? 어떤 단어 끝에서 문자의 모양이 변한다면 이 문자는 다른 문자일까요? 히브리어에서는 다른 문자이고, 아랍어에서는 그렇지 않습니다. 어쨌건 유니코드 컨소시엄의 똑똑한 분들이 수년간 많은 정치적인 토론 등을 통해 이러한 것들을 전부 규정해놓으셨기 때문에 우리는 이와 같은 문제에 대해 전혀 걱정할 필요가 없습니다.
유니코드에서 모든 문자들은 U+0639와 같은 숫자들에 매핑되는데, 이러한 숫자를 코드 포인트라고 합니다. 코드 포인트에서 “U+“는 유니코드를 나타내고, 그 뒤의 숫자는 16진수입니다. U+0639는 아랍어 아인(ع)을 나타내고, U+0041은 대문자 A를 나타냅니다. 각 코드 포인트가 어떤 문자를 나타내는 것인가는 여기에서 보실 수 있습니다.
앞서 말했듯이, 유니코드는 16비트를 사용해서 문자를 나타내는 체계가 아닙니다. 사실, 최초의 유니코드 버전은 16비트 코드 포인트를 사용한 것이 맞지만, 이후에 문자들이 계속 추가되면서 현재는 총 21비트를 사용하고 있습니다. 유니코드는 총 17개의 평면(plane)으로 나뉘어져 있는데, 각 평면의 크기는 16비트라서 평면당 최대 65,536개의 코드 포인트를 저장할 수 있습니다:
-
Plane 0: Basic Multilingual Plane(BMP). 기본 다국어 평면.
0x0000부터0xFFFF까지의 코드 포인트가 저장되는 평면으로, 라틴어, 아시아권 언어, 특수 문자 등을 포함한 대부분의 현대 언어에 사용됩니다.
-
Plane 1: Supplementary Multilingual Plane(SMP). 보조 다국어 평면.
0x10000부터0x1FFFF까지의 코드 포인트가 저장되는 평면으로, 고대 이집트 문자와 같은 옛 문자, 음악 기호, 숫자 기호, 이모지 등에 사용됩니다.
-
Plane 2: Supplementary Ideographic Plane(SIP). 보조 표의문자 평면.
0x20000부터0x2FFFF까지의 코드 포인트가 저장되는 평면으로, 초기 유니코드에 포함되지 않은 한자를 표현하는 데 사용됩니다.
-
Plane 3: Tertiary Ideographic Plane(SMP). 3차 표의문자 평면.
0x30000부터0x3FFFF까지의 코드 포인트가 저장되는 평면으로, 갑골문, 금문, 소전과 같은 옛 상형 문자 등을 위해 예약된 평면으로, 유니코드 13.0부터 글자가 할당되기 시작했습니다.
- Plane 4~13: Unassigned. 미지정 평면.
-
Plane 14: Supplementary Special-Purpose Plane(SSP). 보조 특수 목적 평면.
0xE0000부터0xEFFFF까지의 코드 포인트가 저장되는 평면으로, 제어용 문자에 사용됩니다.
-
Plane 15~16: Private Use Area Plane(PUA). 사용자 정의 영역.
0xF0000부터0x10FFFF까지의 코드 포인트가 저장되는 평면으로, 글꼴 제작자의 의도에 따라 원하는 문자들 할당하여 사용하는 영역입니다. 따라서 호환성이 보장되지는 않습니다.
이제 다음과 같은 문자열을 생각해봅시다:
Hello
유니코드에서 이를 코드 포인트로 나타내면 U+0048 U+0065 U+006C U+006C U+006F가 됩니다. 즉, 본질은 그저 숫자일 뿐이죠. 그럼 이와 같은 것들을 어떻게 메모리에 저장하고, 이메일에서 표현할 수 있을까요?
인코딩 (Encodings)
이것이 바로 인코딩이 하는 역할입니다. 어떤 문자를 저장할 때 앞서 살펴본 코드 포인트를 저장하는 것이 아니라, 코드 유닛(code unit)으로 인코딩하여 저장합니다. 이때 코드 유닛이란 쉽게 말해, 코드 포인트를 특정 인코딩 형식을 통해 변환한 실제 물리적인 비트들이라고 할 수 있습니다.
유니코드 인코딩에 관한 초창기 아이디어는 앞서 소개한 미신과도 연관되어 있습니다. 코드 포인트 숫자들을 그냥 2바이트로 저장하는 것이죠. 이렇게 하면 방금 살펴본 Hello의 코드 포인트는
00 48 00 65 00 6C 00 6C 00 6F
가 되겠죠. 정말로 그럴까요? 이건 어떤가요?
48 00 65 00 6C 00 6C 00 6F 00
물론 이것도 따지고 보면 맞습니다. 엔디안에 따라 첫 번째 방식이 될지, 두 번째 방식이 될지 결정되겠죠.
이렇게 동일한 유니코드를 저장하는 방법이 두 가지가 있었기 때문에, 유니코드 문자열 맨 앞에 FE FF와 같은 문자를 표기하는 기이한 컨벤션이 생기게 되었죠. 이를 Unicode Byte Order Mark라고 합니다.
한동안 이렇게 코드 포인트를 2바이트로 저장하는 방법은 괜찮은 것처럼 보였으나, 곧 미국 개발자들이 “저 0들은 뭐야!” 하며 불평하기 시작했습니다. 왜냐면 이분들은 영문자를 사용했기 때문에 U+00FF보다 큰 코드 포인트를 사용할 일이 드물었기 때문이죠. 이분들 입장에선 문자열 크기를 두 배로 늘리는 것이 탐탁지 않았고, 또 기존의 ANSI나 DBCS character set을 사용하는 문서들은 어떻게 변환할 것인가에 대한 문제도 존재했습니다. 이러한 이유로 대부분의 사람들은 유니코드를 그냥 무시했습니다. 하지만 그로 인해 문제들은 더욱 심각해져만 갔죠.
이때 UTF-8이라는 훌륭한 개념이 등장합니다. UTF-8은 바이트 단위로 문자열의 유니코드 코드 포인트를 저장하는 방식입니다. 0~127에 해당하는 코드 포인트들은 오직 1바이트에 저장되고, 128 이상의 코드 포인트들은 최대 6바이트를 사용하여 저장됩니다.
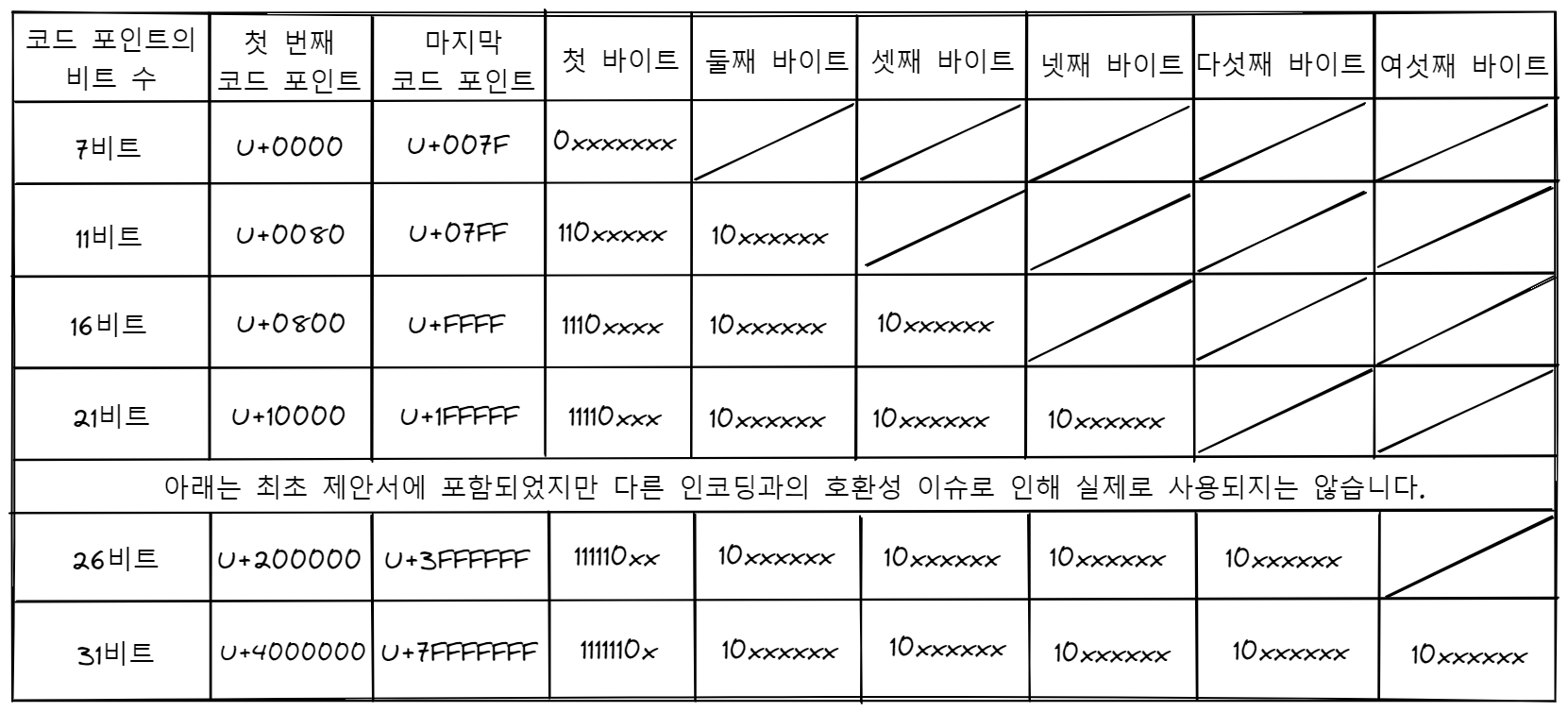
UTF-8의 장점 중 하나는 영문자들이 ASCII에서 그랬던 것과 완전 똑같이 표현된다는 것입니다. 앞서 살펴본 Hello의 경우 유니코드가 U+0048 U+0065 U+006C U+006C U+006F 였는데, 이를 UTF-8 인코딩으로 저장하면 48 65 6C 6C 6F가 됩니다. 이는 ASCII, ANSI, 그리고 여타 다른 OEM character set과 완벽히 동일하죠. 악센트가 표시된 영문자나 그리스어 같은 문자를 사용하는 경우 하나의 코드 포인트를 저장하기 위해 몇 바이트를 추가로 더 사용하면 됩니다. 또한, UTF-8을 사용하면 하나의 0바이트를 null-terminator로 사용하고자 했던 구식의 문자열 처리 코드가 문자열을 잘라내지 않는다는 장점이 있습니다.
이외에도 유니코드를 인코딩하는 방식에는 여러 가지가 있습니다. UTF-8과 거의 흡사하지만 최상위 비트가 0인 UTF-7도 있고, 코드 포인트를 4바이트로 통일하여 저장하는 UCS-4 방식도 있습니다. 하지만 실제로 사용되지는 않습니다.
그리고 사실은 유니코드 코드 포인트를 예전 방식의 인코딩 방식을 사용하여 인코딩할 수는 있습니다. 예를 들어 Hello문자열을 ASCII, 예전 그리스어 OEM, 히브리어 ANSI 혹은 기타 여러 가지 인코딩 방식을 이용하여 인코딩할 수는 있죠. 하지만 몇몇 문자열이 깨지는 문제가 발생할 수 있습니다. 여러분이 나타내고자 하는 유니코드 코드 포인트에 상응하는 것이 이러한 인코딩에 없다면 물음표 ”?” 혹은 �와 같은 글자가 표시될 것입니다. 혹은 이상한 글자들이 튀어나올 수도 있구요.
기존의 인코딩 방식 중엔 몇몇 코드 포인트만 제대로 저장하고 나머지는 물음표를 표시하는 것이 많습니다. 예를 들어 영문자를 표시하는 데 흔히 사용되는, 속칭 Latin-1이라고 불리는 ISO-8859-1 인코딩을 이용하여 러시아어나 히브리어를 나타내려고 하면 대부분의 글자가 깨질 것입니다. 하지만 UTF-7, 8, 16, 32 인코딩 방식 모두 어떠한 코드 포인트도 정확하게 나타낼 수 있습니다.
인코딩에 관한 가장 중요한 사실 한가지
만약 앞서 제가 알려드린 내용들을 모두 까먹으신다고 해도, 이것만은 꼭 기억해주세요: 인코딩도 모르면서 문자열을 사용하는 것은 말이 안됩니다. 더 이상 모래 속에 머리를 파뭍은채 "일반 텍스트(plain text)" == ASCII라고 생각하시면 안 됩니다!
일반 텍스트라는 것은 존재하지 않습니다.
메모리, 파일, 혹은 이메일에 저장된 문자열이 어떤 인코딩 방식을 써서 저장되었는가를 모르신다면 이를 해석할 수도 없고 유저들에게 제대로 보여줄 수도 없을 것입니다.
“제 사이트가 깨져서 보여요” 혹은 “악센트 기호를 썼을 때 이메일이 깨져서 보인대요”와 같은 거의 대부분의 멍청한 문제들은 문자열을 어떤 인코딩 방식으로 인코딩했는지에 대해 알려줘야 하는 것도 모르는 무지한 프로그래머로 인해 생깁니다.
그럼 문자열이 어떤 인코딩 방식을 사용하는지 어떻게 알려줄 수 있을까요? 이메일의 경우 다음과 같은 헤더를 통해 알려줄 수 있습니다:
Content-Type: text/plain; charset=“UTF-8”
웹페이지의 경우, 다음과 같이 <meta> 태그를 이용하여 인코딩 정보를 포함할 수 있습니다:
<meta charset="UTF-8">
혹은,
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">이에 대해 “그럼 해당 <meta> 태그 전까지의 HTML 파일은 어떻게 읽을 수 있나요?”라고 궁금해하실 수도 있겠습니다. 다행히도 코드 포인트 32부터 127까지는 대부분의 인코딩 방식이 동일하기 때문에 그다지 걱정하실 필요가 없습니다.
하지만 브라우저가 해당 <meta> 태그를 보는 순간 기존의 파싱을 중단하고 명시된 인코딩으로 다시 해석을 하므로 인코딩 정보가 담긴 <meta> 태그는 반드시 <head> 태그의 최상단 쪽에 위치해야 합니다 (W3C에 따르면 반드시 파일의 첫 1,024바이트 내에 포함되어야 하므로, <head> 태그를 열자마자 표기하는 것을 추천하고 있습니다. 또한 이 문서에 따르면 인코딩 방식으로 UTF-8를 사용하는 것을 적극 권장하고 있습니다).
만약 인코딩 정보가 HTTP 헤더에도, HTML 파일에도 없다면 브라우저는 인코딩 방식을 추측합니다만, 정확도는 보장할 수 없습니다.