컴퓨터 구조 - 성능 이슈
카테고리: Computer ArchitectureMarch 23, 2021
성능을 위한 설계
컴퓨터의 성능대비 가격은 시간에 따라 큰 폭으로 하락해왔습니다. 일례로, 현재의 노트북 성능이 10~15년전의 IBM 메인프레임 컴퓨터와 맞먹는 정도입니다. 그리고 이러한 기술적 진보덕분에 더 복잡하고 강력한 프로그램 개발이 가능해졌습니다.
컴퓨터 architecture및 organization 관점에서 흥미로운 점은, 현재 컴퓨터의 기초를 이루고 있는 근간들이 50여년 전의 IAS 컴퓨터와 크게 다를바 없지만 하드웨어 성능을 최대로 이끌어내기 위한 기술들이 더 정교해졌다는 점입니다. 즉, 논리적 구조(architecture)는 크게 달라진 것이 없지만 하드웨어(organization)가 그만큼 발전했다는 뜻입니다.
마이크로 프로세서(Microprocessor) 속도
프로세서 제조사들은 하나의 칩에 더 많은 트랜지스터를 집적하는 등의 노력을 통해 프로세서의 하드웨어 성능을 지속적으로 발전시켜왔습니다. 하지만 프로세서를 제대로 활용하지 못한다면, 즉 프로세서가 놀게끔 놔두지 않고 끊임 없이 일을 시키지 못한다면 아무리 프로세서 하드웨어가 발전했다고 해도 무용지물이 되버립니다.
이에 따라 제조사들이 공정을 개선하는 동안 프로세서 설계자들은 프로세서의 효율을 높이기 위해 노력해왔는데, 어떠한 기법들을 사용했는지 간략히 살펴봅시다:
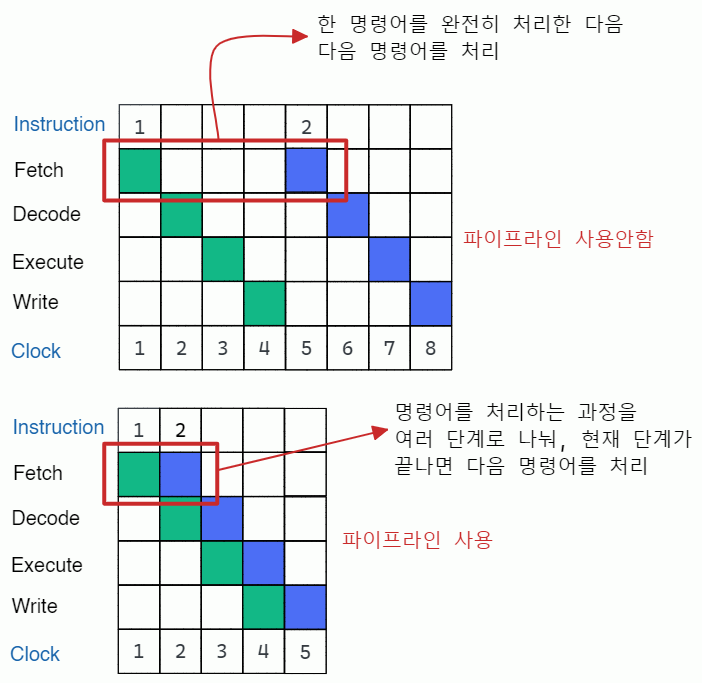
파이프라이닝(Pipelining): 쉽게 말해 명령어를 처리할 때 분업화하여 처리하는 것을 말합니다. 즉, 명령어 처리 단계를 여러 단계로 나눠 각기 다른 단계에 있는 여러 명령어를 동시에 처리하는 기술입니다. 흔히fetch,decode,read,execute,write back등의 단계로 나누는데,fetch단계에서는 메모리로부터 명령어를 fetch만 하고 명령어를 다음 단계로 넘긴 다음 다른 명령어를 fetch 합니다. 마찬가지로,decode단계 역시 decode만 수행하고 명령어를 다음 단계로 넘기고 다른 명령어를 또 decode 합니다. 만약 파이프라이닝을 사용하지 않는다면 한 명령어를 가져와 해석하고 실행해서 마무리할 때까지 이후의 명령어는 기다려야 하므로 시간 낭비가 발생합니다.
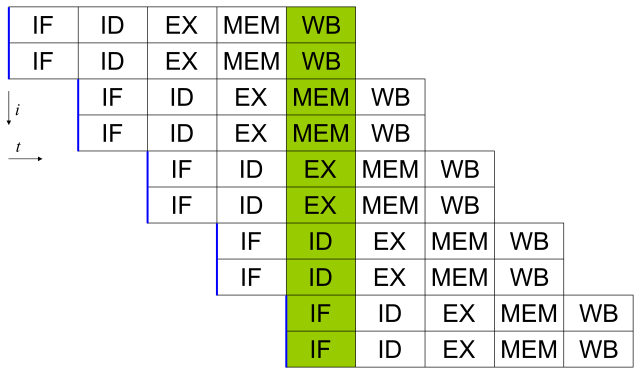
분기 예측(Branch Prediction):if 문과 같은 분기 명령에 대해, 어디로 jump할 것인가를 예측하여 jump될 위치(주소)에 있는 명령어를 미리 가지고 와서(prefetch) 버퍼에 저장하는 기술입니다.슈퍼스칼라(Superscalar Execution): 각 클럭 사이클마다 두 개 이상의 명령어를 issue(명령어를 CPU 프론트엔드에서 CPU 백엔드로 보내는 것) 하는 기술입니다. 이를 위해 여러 개의 파이프라인이 병렬로 사용됩니다.
데이터 흐름 분석(Data Flow Analysis): 명령어, 데이터 등의 의존성을 분석해서 명령들을 최적의 순서로 스케줄링하는 기술로, 원래의 순서와 무관하게 명령어들이 준비되었을 때 실행되게끔 스케줄 됩니다.예측 실행(Speculative Execution): 분기 예측과 데이터 흐름 분석 등을 활용하여, (추측을 통해) 다음번에 수행될 것 같은 명령어를 미리 가져와서 실행하여 그 결과를 임시 저장소(temporary locations)에 저장합니다. 다음의 코드를 살펴봅시다:
if (a <= 1) {
b = 2;
}위 코드에서, a <= 1을 판단하기 위해 a의 값을 읽는 데 시간이 걸린다고 하면 미리 b = 2를 실행하여 성능 향상을 꾀하는 것이 바로 예측 실행 기법입니다.
종합적으로 보자면, 위 기법들은 본질적으로 한 사이클당 최대한 많은 명령을 수행하도록 하여 프로세서의 효율을 높이는 데 사용됩니다. 즉, 프로세서가 놀게끔 놔두지 않겠다는 것이죠 🙀
성능 밸런스 (Performance Balance)
여태껏 프로세서의 성능은 가히 엄청난 속도로 발전해왔지만, 메인 메모리와 같은 다른 주요 부품들은 그에 미치지 못했습니다. 이렇게 컴퓨터의 일부분은 빠르지만, 다른 부분은 그렇지 못하다면 컴퓨터 전체의 성능은 느린 부분에 의해 좌우됩니다.
따라서 부품간의 성능 차이를 최소화하는 것이 전체적인 성능 향상에 중요한데, 예를 들어 프로세서와 메인 메모리를 생각해봅시다. 메모리가 프로세서의 성능을 따라가지 못해 명령·데이터가 메모리에서 프로세서로 전달되는 속도가 느리다 보니, 프로세서가 처리할 수 있는 용량보다 더 적은 양의 명령·데이터가 전달되어 결국 프로세서의 효율이 떨어지게 됩니다.
이러한 성능 간의 밸런스 문제를 해결할 수 있는 몇 가지 방법들을 살펴봅시다:
- 메모리를 “deep”하게 만들기보다, “wide”하게 만듦으로써 한 번에 읽을 수 있는 비트수를 증가시킵니다.
- 캐싱을 활용하여 메인 메모리에 접근하는 빈도수를 줄입니다.
- 더 빠른 버스와 버스 계층 구조를 활용하여 프로세서와 메인 메모리 간의 대역폭(bandwidth)를 높입니다.
또한, I/O 장치들을 어떻게 다룰 것인가도 중요한데, 컴퓨터가 더욱 빨라지고 더욱 다양한 동작들을 수행할 수 있게 됨에 따라 주변장치들(모니터, 키보드, 마우스, 프린터 등)과 I/O 동작을 하는 경우가 많아졌습니다. 물론 현대의 프로세서들은 이러한 장치들로부터 받아온 데이터를 능숙하게 처리할 수 있지만, 문제는 I/O장치와의 데이터를 주고받는 것이 느리다는 점입니다. 이 문제를 해결하기 위해 캐싱, 버퍼링과 같은 방법 및 더 빠른 버스, 더 정교한 연결 구조를 사용하곤 합니다. 더 나아가서, 멀티 프로세서 구조를 사용하면 이러한 I/O 처리를 좀 더 원활하게 할 수 있습니다.
칩 구조와 구성 개선
앞서 살펴본 것처럼 프로세서와 장치들간의 성능 밸런스를 맞추는 것도 중요하지만, 프로세서 그 자체의 성능을 높이는 것도 여전히 중요합니다. 프로세서의 성능을 높이기 위한 세 가지 방법들을 간략히 살펴보자면 다음과 같습니다:
- 프로세서 하드웨어 그 자체의 성능을 높이는 방법이 있습니다. 즉, 미세공정을 이용하여 하나의 칩에 들어가는 반도체 소자의 개수를 늘리고 클럭을 높이는 것입니다.
- 프로세서와 메인 메모리 사이에 존재하는 캐시 메모리들의 용량과 속도를 높이는 방법이 있습니다.
- 명령 실행 속도를 높이기 위해 프로세서의 구조와 구성을 개선하는 방법이 있습니다. 흔히 병렬성(parallelism)을 이용하는 방법을 많이 사용합니다.
전통적으로 프로세서 성능 향상에 가장 큰 영향을 미친 요인은 클럭 스피드와 집적도(logic density)였습니다. 하지만 클럭 스피드가 높아지고 집적도가 높아질수록 다음과 같은 사항이 장애물로 작용하게 됩니다:
-
소비전력(Power): 클럭 스피드와 집적도가 높을수록 소비전력이 높아지고, 이로 인해 열이 많이 발생하게 됩니다. 일반적으로 소비전력은 전기용량(capacitance), 전압(voltage), 진동수(frequency)에 대해 다음과 같은 비례관계를 형성합니다:
소비전력(P) ∝ 전기용량(C) × 전압(V)2 × 진동수(f)
즉, 집적도가 높아지면 전기용량이 증가하고, 클럭 스피드가 증가하면 진동수가 증가하는데, 위 식에서 알 수 있듯 이 두 값이 커질수록 이에 비례하여 소비전력도 높아짐을 알 수 있습니다.
- RC Delay: 전자가 이동하는 속도는 저항(resistance)과 전기용량이 커질수록 느려지는데, 위에서 살펴봤듯이 집적도 증가할수록 전기용량이 증가하고, 또 각 소자들의 크기 혹은 소자를 연결하는 전선들의 크기가 작아질 수록 저항도 증가하게 됩니다. 이러한 요인들 때문에 RC Delay가 증가하게 됩니다.
- Memory Latency and Throughput: 프로세서의 속도가 빨라짐에 따라 상대적으로 메모리 접근 속도(latency)와 전송 속도(throughput)가 느려지게 됩니다.
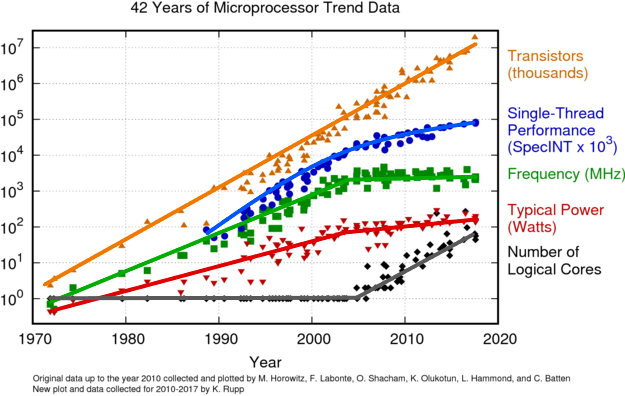
위 그림에서 볼 수 있듯, 소비 전력(power)을 줄이기 위해 어느 순간부터 클럭 스피드(frequency)가 더 이상 증가하지 않는다는 사실을 알 수 있습니다. 대신, 프로세서의 성능을 높이기 위해 코어의 개수를 늘리는 방법을 사용하고 있음을 알 수 있습니다.
멀티코어
이처럼 멀티코어 방식을 사용하면 클럭 스피드를 높이지 않고도 프로세서의 성능을 높일 수 있습니다. 여러 연구에 따르면, 프로세서 성능은 프로세서 복잡도의 루트(square root)에 비례해서 향상된다고 합니다. 하지만 멀티코어를 잘 활용할 수 있도록 프로그램을 만들면 코어 개수에 비례해서 성능이 향상됩니다. 이에 따라 복잡한 코어를 하나 사용하기보다, 간단한 코어를 여러 개 사용하는 방식으로 프로세서가 진화한 것입니다.
또한, 코어를 복잡하게 만들기보다 코어 수를 늘리는 방식을 사용하면 더 큰 캐시 메모리를 사용할 수 있게 됩니다. 메모리가 사용하는 소비전력이 코어보다 적기 때문인데요, 코어를 복잡하게 만드는 대신 단순한 코어를 여러 개 사용하면 그만큼 코어가 사용하는 소비전력을 줄일 수 있고, 이렇게 절약한 소비전력을 캐시 메모리가 사용하도록 할 수 있기 때문입니다.
물론 이러한 성능 향상은 프로그램이 여러 개의 코어를 잘 활용할 수 있다는 전제하에 이뤄질 수 있습니다. 프로그램이 수행하는 작업을 병렬화해야지만 여러 개의 코어를 사용하는 이점을 살릴 수 있다는 것입니다. 따라서 프로그램을 설계할 때 여러 개의 코어를 사용할 수 있도록 병렬화를 잘하는 것이 중요합니다.
암달의 법칙 (Amdahl’s Law)
암달의 법칙은 Gene Amdahl이 만든 법칙으로, “한 시스템의 일부를 개선할 때 시스템 전체적으로는 얼마만큼의 성능 향상이 있는가?” 에 관한 내용입니다.
이 법칙에 따르면, 어떤 시스템을 개선하여 전체 작업 중 f만큼 차지하는 부분을 N만큼 향상시키면 시스템 전체적으로 1 / (1 - f) + (f / N)만큼의 성능 향상이 이뤄집니다:

이 식으로 부터 다음 두 가지를 도출할 수 있습니다:
- 어떤 부분 시스템이 전체 시스템에서 차지하는 비중
f가 작을수록, 부분 시스템을 최적화했을때 전체 시스템이 향상되는 정도가 미미해집니다. N이 무한대라고 하면, 전체 시스템 성능 향상은 최대1 / (1 - f)만큼 가능합니다. 즉, 부분 시스템을 아무리 최적화해도 전체 시스템의 성능은 최대1 / (1 - f)만큼 향상됩니다. 프로세서로 예를 들면, 코어의 개수N을 아무리 늘린다고 해도 전체적인 성능이 향상되는 정도에는 한계가 있습니다.
리틀의 법칙 (Little’s Law)
John Little에 의해 발명된 이 법칙은 어떤 시스템이 정상 상태(steady state)에 도달했을 때, 여러 가지 작업들의 대기시간, 서비스 시간들을 설명해주는 법칙입니다. 주로 성능 평가에 많이 사용되며, 식은 다음과 같습니다:
L = λW
L: 한 시스템 내의 평균 아이템의 수λ: 각 아이템들의 평균 도착 속도W: 시스템에서 각 아이템의 평균 대기 시간
예를 들어 2시간 동안 320명의 손님이 다녀간 식당에서 각 손님의 평균 식사 시간이 15분이라 할 때, 리틀의 법칙을 이용하여 식당 안의 “평균 손님 수”를 구할 수 있습니다:
λ: 320명 / 2시간 → 160명 / 1시간W: 15 / 60분 → 1 / 4시간
이므로, L = λW에 대입해보면 평균 손님수 L은 160 × (1 / 4) = 40명이 됩니다.
즉 요약하자면, 정상 상태(프로세스가 안정적인 상태)일 때 queueing 시스템에 존재하는 평균적인 아이템의 수는 아이템이 시스템에 들어오는 수와 아이템이 평균적으로 시스템에서 머무르는 수를 곱한것과 같다는 의미입니다.