컴퓨터의 메모리 시스템
카테고리: Computer ArchitectureApril 01, 2021
컴퓨터가 사용하는 메모리는 하나의 단일 메모리로 구성되어 있는 것이 아니라, 여러 메모리가 하나의 시스템을 이뤄 동작합니다. 이 포스트에선 이러한 메모리 시스템을 간단히 살펴보겠습니다.
컴퓨터 메모리 시스템 개요
컴퓨터의 복잡한 메모리 시스템을 다음과 같이 분류하여 생각해볼 수 있습니다:
-
위치(location):내부에 위치(internal): 컴퓨터 내부에 고정(fixed)되어 있는 메모리로, “내부 메모리”라고 하면 흔히 메인 메모리를 일컫지만, 메인 메모리 이외에도 레지스터, 캐시 메모리 등이 존재합니다.외부에 위치(external): 주변 저장 장치(peripheral storage device)를 의미하며, HDD, SSD 등이 있습니다. CPU는 I/O 컨트롤러를 통해 이 장치들에 접근합니다.
-
용량(capacity):- 내부 메모리의 경우, 용량을 보통 워드 단위로 나타냅니다. 이때 워드(word)란, CPU의 데이터 버스의 width로서 한 번에 전송될 수 있는 데이터의 크기를 의미합니다. CPU가 한 사이클에 처리할 수 있는 데이터의 크기라고도 할 수도 있는데, 32비트 CPU의 경우 워드의 크기는 일반적으로 32비트, 64비트 CPU의 경우 워드의 크기는 (일반적으로) 64비트입니다.
- 외부 메모리들의 경우 용량을 보통 바이트 단위로 나타냅니다.
전송 단위(unit of transfer): 한 번에 전송되는 데이터의 단위를 의미하며, 내부 메모리의 경우 일반적으로 워드 혹은 주소 단위이며 외부 메모리의 경우 일반적으로 블록 단위입니다.-
접근 방법(access method):순차 접근(sequential access): magnetic 테이프와 같이, 1번째에 접근하고 그다음 2번째, 그다음 3번째, ⋯ 와 같이 “순차적”으로 접근하는 방법입니다.직접 접근(direct access): HDD에서 주로 사용되는 방식으로, 각 블록(혹은 record)들이 물리적인 위치를 바탕으로 고유의 주소를 가지며 원하는 데이터가 저장된 장소 근처로 이동한 다음 순차 검색을 통해서 데이터에 접근하는 방법입니다. 접근 시간(access time)은 현재 접근하고자 하는 데이터의 위치와 이전에 접근했던 데이터의 위치에 따라 결정됩니다.임의 접근(random access): 주로 메인 메모리에서 사용되는 방식으로, 메모리의 각 위치는 고유의 주소로 식별이 가능하며 이 주소를 통해 데이터가 어떤 위치에 있던지 관계없이 항상 상수 시간(constant time)에 데이터 접근이 가능합니다.연상 접근(associative): 주로 캐시 메모리에서 사용되는 방식으로, 접근하고자 하는 데이터의 내용을 통해 이 데이터가 저장된 위치를 식별할 수 있습니다.
-
성능(performance):접근 시간 (access time, or latency): 메인 메모리의 경우 접근 시간은 읽기/쓰기 연산을 수행하는 시간을 의미합니다. 이외의 메모리의 경우, 읽기/쓰기 메커니즘을 원하는 위치에 배치(position)하는 데 걸리는 시간을 의미합니다.메모리 사이클 시간(memory cycle time): 주로 메인 메모리에 해당하는 개념으로, 접근 시간 + 두 번째 접근을 시작하기 전에 소요되는 시간을 의미합니다. 시스템 버스와 관련이 있습니다.전송률(transfer rate): 한 메모리 단위로 데이터를 전송하거나 전송받는 비율을 의미합니다. 메인 메모리의 경우전송률 = 1 / 사이클 타임이며, 랜덤 엑세스 방식이 아닌 메모리의 경우 전송률 R은 다음과 같습니다:-
R = n / (Tn - TA)
- Tn: n비트를 읽거나 쓰는데 걸리는 평균시간.
- TA: 평균 엑세스 타임.
- n: 비트 수.
메모리 계층(Memory Hierarchy)
컴퓨터 메모리 시스템을 설계할 때, 메모리의 용량, 접근 속도, 가격을 주로 고려합니다. 이 세 가지 요인들 간엔 trade-off가 존재하는데, 일반적으로 아래의 관계가 성립합니다:
- 속도가 빠를수록 한 비트당 가격이 비싸집니다.
- 용량이 클수록 한 비트당 가격이 싸집니다.
- 용량이 클수록 속도가 느려집니다.
위 세 가지 관계를 생각해봤을 때, 용량을 키우고 가격을 싸게 하자니 속도가 느려지고, 속도를 높이자니 용량이 적어진다는 점이 있습니다. 이러한 한계를 극복하기 위해 하나의 메모리를 사용하는 것이 아니라 여러 개를 사용하여 메모리 계층을 구성하면 용량이 크고 속도가 빠른 하나의 메모리를 사용하는 것과 같은 효과를 누릴 수 있습니다.
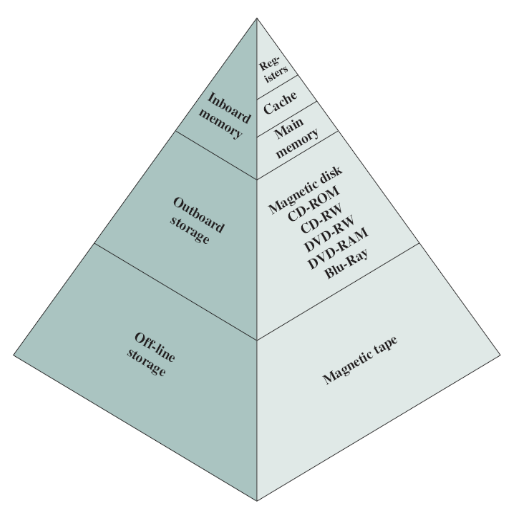
메모리 계층은 일반적으로 아래 그림과 같이 구성됩니다. 이때, 아랫단으로 내려갈수록:
- 한 비트당 가격이 저렴해집니다.
- 용량이 커집니다.
- 속도가 느려집니다.
- CPU에 의한 접근 횟수가 줄어듭니다.
지역성의 원리(Locality of Reference)
앞서 살펴본 메모리 계층은 무작정 구성한 것이 아니라, 지역성의 원리라는 것에 기반을 두고 설계된 방식입니다. 지역성의 원리에는 크게 두 가지가 존재합니다:
시간 지역성(temporal locality): 최근에 참조한 데이터(혹은 명령어)는 가까운 미래에 다시 참조될 가능성이 높은 것을 의미합니다. 예를 들어, 루프 문을 실행하는 경우 특정 변수 혹은 명령어를 반복해서 참조하게 됩니다.공간 지역성(spatial locality): 최근에 참조한 데이터(혹은 명령어) 근처에 존재하는 데이터(혹은 명령어)를 가까운 미래에 참조할 가능성이 높은 것을 의미합니다. 예를 들어, 배열을 사용하는 경우 일반적으로 현재 접근한 원소의 근처에 있는 원소를 참조하게 됩니다.
코드 예시:
sum = 0;
for (i = 0; i < n; i++) {
sum += a[i];
}
return sum;- 시간 지역성:
i와sum을 각 순회마다 참조하고 있습니다. - 공간 지역성: 배열
a의 원소들을 순차적으로 참조하고 있습니다.