캐시 메모리
카테고리: Computer ArchitectureApril 02, 2021
캐시 메모리의 사용 이유?
캐시 메모리는 주로 메인 메모리의 DRAM보다 작고 빠른 SRAM으로 만들어진 메모리입니다. 앞선 포스트에서 살펴본 지역성의 원리에 근거하여, 자주 사용하는 데이터를 메인 메모리보다 더 빠른 캐시 메모리에 위치시켜 CPU의 데이터 접근 성능을 높이기 위해 사용됩니다.
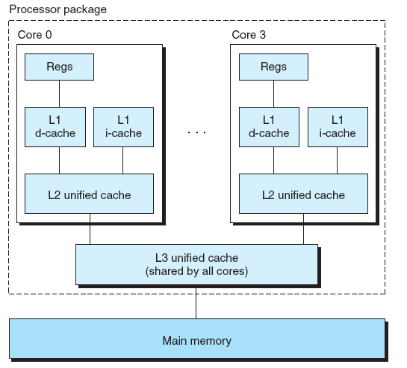
현대의 일반적인 CPU는 대개 각 코어마다 L1, L2 캐시가 있고, 모든 코어가 공유하는 L3 캐시가 존재합니다. 논리적으론 CPU와 메인 메모리 사이에 위치한다고 볼 수 있지만, 사실 좀 더 넓게 생각해보면 메모리 계층에서 각 계층은 바로 아래 계층의 캐시 메모리의 역할을 합니다. 따라서 SRAM으로 만들어진 물리적인 캐시 메모리뿐만 아니라, 보조 기억장치의 캐시 메모리 역할을 하는 메인 메모리, 클라우드 저장소의 캐시 메모리 역할을 하는 보조기억장치도 넓은 의미에서의 캐시 메모리라고 할 수 있습니다.
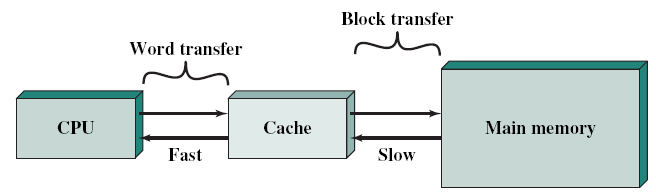
CPU가 워드 단위의 메모리를 읽으려고 할 때 우선 캐시 메모리부터 살펴봅니다. 만약 읽고자 하는 데이터가 캐시 메모리에 있다면 캐시 메모리에 저장된 데이터를 사용하고, 만약 캐시 메모리에 없다면 메모리에서 (여러 워드 단위로 구성된) 블록 단위로 데이터를 읽어와 캐시에 저장하고 원하는 데이터를 사용합니다. 이때 메모리에서 원하는 데이터만이 아니라 블록 단위로 오는 이유는 공간 지역성의 원리를 활용하기 위함이라고 할 수 있습니다.
캐시 주소(Cache Address)
대부분의 CPU(및 운영체제)는 가상 메모리(virtual memory)를 사용합니다. 이는 프로그램으로 하여금 물리적으로 사용할 수 있는 메모리 양과 관계없이 논리적인 관점에서 메모리를 사용하도록 하여 사실상 메모리가 무한정 존재하는 듯한 효과를 제공합니다.
가상 메모리를 사용할 땐 가상 주소(virtual address)를 사용하는데, CPU가 메인 메모리에 접근할 때 이 가상메모리를 MMU(Memory Management Unit)라는 장치를 통해 실제 메인 메모리의 물리적인 주소로 변환해야만 합니다. 이를 고려해 봤을 때, 다음과 같이 캐시를 CPU와 MMU사이에 둘 수도 있고 MMU와 메인 메모리 사이에 둘 수도 있습니다:
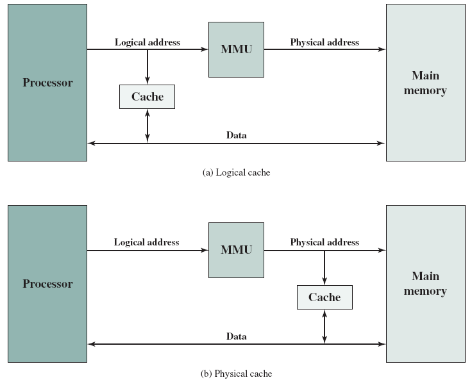
위 그림 (a)의 논리 캐시(logical cache, or virtual cache)는 가상 주소를 사용해서 데이터를 저장하는 방식으로, CPU는 MMU를 거치지 않고 직접 캐시에 접근합니다. 반대로, (b)의 물리 캐시(physical cache)는 메인 메모리의 물리적인 주소를 사용해서 데이터를 저장하는 방식입니다.
논리 캐시의 장점은 MMU를 거치지 않기 때문에 물리 캐시보다 접근 속도가 빠르다는 점입니다. 하지만 가상 메모리 시스템의 경우, 서로 다른 프로세스가 똑같은 가상 주소를 사용할 수도 있기 때문에 이에 대한 처리가 필요합니다.
다시 말해, 각각 프로세스의 가상 메모리는 모두 0번지에서 시작되는데, 이때 서로 다른 두 프로세스 간의 동일한 가상 주소는 다른 물리적인 주소를 가리킵니다. 예를 들어, 프로세스 A의 가상 메모리 100번지는 실제 물리 주소 50번지를 가리키고, 프로세스 B의 가상 메모리 100번지는 실제 물리 주소 200번지를 가리킵니다. 이에 따라 캐시 메모리는 컨텍스트 스위칭이 일어나게 되면 캐시에 있던 데이터를 전부 비우고(flush) 사용해야 한다는 단점이 있습니다.
캐시 메모리 구조
아래 그림은 캐시 메모리의 일반적인 구조를 나타냅니다:
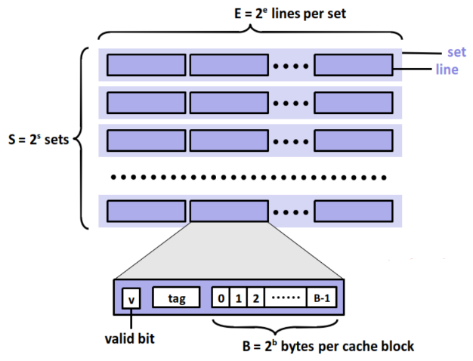
캐시 메모리는 S 개의 집합(set)으로 이루어져 있고, 각 집합에는 E 개의 캐시 라인(cache line)이 존재하는데, 이때 캐시 라인은 메인 메모리의 블록과 같은 개념이라고 볼 수 있습니다. 각 캐시 라인은 메인 메모리로부터 가져온 블록 뿐만 아니라, 해당 블록이 유효한지를 나타내는 유효(valid) 비트, 그리고 동일한 집합에 들어올 수 있는 여러 블록들을 구분하기 위한 태그와 같은 정보를 추가로 저장합니다.
따라서 메인 메모리의 각 블록이 B 바이트 라고 한다면 캐시 메모리의 전체 사이즈는 S × E × B (set의 개수 × 각 set에 들어있는 line의 개수 × 각 라인에 들어있는 블록의 크기)입니다.
각 캐시 라인에 저장되는 태그의 역할을 살펴보겠습니다. CPU로부터 입력받는 메모리 주소가 m 비트(m = t + s + b)로 표현되고, 메모리의 전체 크기를 M 바이트(=2m)라고 한다면, 메모리 주소를 다음과 같은 구조로 생각해볼 수 있습니다:
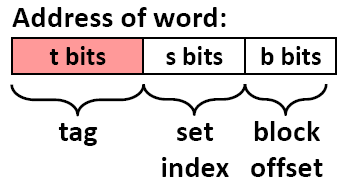
- 메인 메모리의 각 블록의 크기가 B = 2b 바이트 이므로, 메인 메모리에 있는 총 블록의 개수는 M / B 개 입니다.
- m 비트 주소에서, 하위 b 비트는 캐시 라인에 있는 블록 내의 바이트 오프셋을 나타냅니다. 즉, 현재 접근하고자 하는 데이터의 블록 상에서의 위치를 나타낸다고 볼 수 있습니다.
- s 비트는 블록의 어느 set에 들어가는지를 나타냅니다.
- t 비트는 동일한 set에 들어갈 수 있는 여러 개의 블록들을 구별합니다.
캐시 읽기 과정
(앞서 잠깐 언급했듯이) CPU가 한 워드 사이즈만큼의 데이터를 메모리로부터 읽고자 할 때, 바로 메모리로 가서 데이터를 읽는 것이 아니라 우선은 캐시 메모리에 해당 워드가 존재하는지를 살펴봅니다. 만약 캐시 메모리에 찾고자 하는 워드가 있다면 CPU는 해당 워드를 읽습니다.
하지만 만약 현재 살펴보고 있는 레벨의 캐시 메모리에 캐싱 된 데이터가 없다면, 그다음 레벨의 캐시 메모리로 가서 데이터가 있는지 살펴보고, 데이터가 있으면 해당 데이터를 이전 레벨의 캐시에 저장하고 가져온 데이터를 CPU가 사용합니다. 만약 모든 레벨의 캐시 메모리를 다 살펴봐도 없다면, 메인 메모리에 가서 (일정 크기의 워드 크기로 구성된) 블록 단위만큼 데이터를 가져와 캐시에 저장하고, 가져온 데이터를 CPU가 사용합니다.
CPU가 참조하고자 하는 메모리 주소를 캐시 메모리에 입력하면 다음의 순서로 요청된 블록을 탐색합니다:
- 메모리 주소의 s 비트를 바탕으로 해당 블록의 set을 찾습니다.
- 해당 set에서 tag비트 값과 동일한 태그값을 갖는, 유효한(즉, 유효 비트가 1인) 캐시 라인이 존재하는지 탐색합니다.
-
만약 발견된다면 캐시 히트(cache hit)이고, 그렇지 않으면 캐시 미스(cache miss)입니다.
- 캐시 히트인 경우, 메모리 주소의 하위 b 비트와 읽을 개수를 나타내는 컨트롤 정보를 바탕으로 요청된 바이트 배열을 찾아 데이터를 사용합니다.
- 캐시 미스인 경우, 다음 레벨의 메모리(다른 캐시 메모리일 수도 있고, 메인 메모리일 수도 있습니다)로 가서 원하는 데이터가 포함된 블록을 가져옵니다. 이 경우, 만약 현재 레벨의 캐시 메모리가 꽉 차 있으면 특정 블록을 쫓아내고(evict) 새로운 블록을 저장하는데, 어떤 블록을 쫓아낼 것인가는 교체 정책(replacement policy, or evicting policy)에 따라 차이가 있습니다. 교체 정책은 잠시 뒤에 살펴보겠습니다.
Direct Mapped Cache
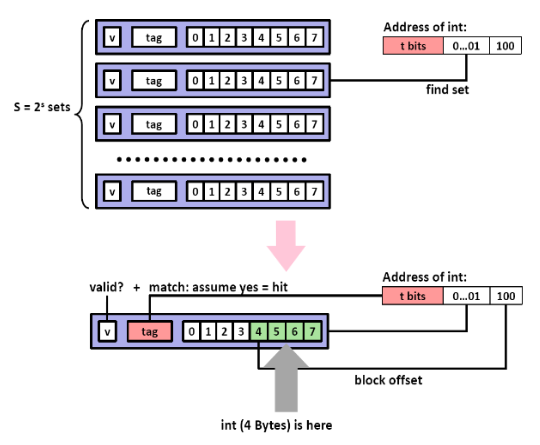
Direct Mapped Cache는 각 set에 캐시 라인이 하나만 존재하는 캐시 구조입니다.
Direct mapped cache에서 원하는 데이터를 찾는 과정은 다음과 같습니다:
-
set selection: 주소의 s 비트를 이용해서 일치하는 set을 찾습니다.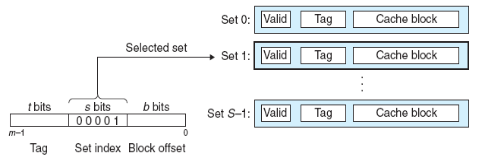
Direct mapped 캐시에서의 Set 찾기. 출처: Computer Systems a Programmer's Perspective (3rd Edition) -
line matching: 1번 과정을 통해 찾은 set의 캐시 라인의 태그와 현재 주소의 태그 비트 t 를 비교하여 캐싱 된 데이터가 찾고자 하는 데이터인지 판별합니다. 또한, 유효 비트를 통해 유효성을 검사합니다. 따라서, 주소의 태그 비트 t와 set에 저장된 태그 비트가 같고, 유효 비트가 1인 경우 캐시 히트가 발생했다고 할 수 있습니다.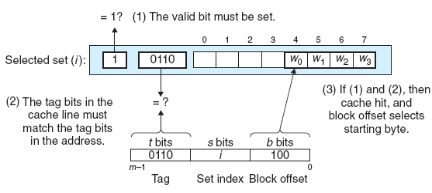
Direct mapped 캐시에서의 line 매칭. 출처: Computer Systems a Programmer's Perspective (3rd Edition) word selection: 만약 2번 과정에서 캐시 히트가 발생했다면, 우리가 원하는 데이터가 캐싱 된 블록 내 어딘가에 존재한다는 것을 알 수 있습니다. 이 단계는 원하는 데이터가 블록의 어디에 있는지를 찾아내는 단계인데, 위 그림에서 보듯이 블록 오프셋 비트 b 를 통해 해당 데이터의 위치를 찾아냅니다. 이는 마치 배열에서 인덱싱하는 것과 유사한데, 위 그림에서 블록 오프셋 비트 1002가 의미하는 것은 우리가 원하는 데이터가 시작 위치(0번째 인덱스)를 기준으로 4번째 인덱스에 존재한다는 뜻입니다. 즉, 위 그림의 경우 4번째 인덱스에 있는 W0이 우리가 찾고자 하는 워드가 됩니다.
Direct Mapped Cache 방법은 하드웨어 구조 및 구현 방법이 간단하지만 비효율적입니다. 만약 같은 set에 들어가는 특정 블록들만 계속해서 참조한다면 캐시의 다른 곳은 비어있음에도 불구하고 특정 set만 계속 참조함으로써 캐시 미스가 지속해서 발생할 수 있다는 단점이 있습니다.
Set Associative
앞서 살펴본 Direct mapped 캐시의 문제는 본질적으로 각 set당 오직 하나의 캐시 라인만 존재함으로 인해 발생한 문제였습니다.
여기서 살펴볼 Set associative 방식은 하나의 set이 여러 개의 라인을 가짐으로써 위의 문제점을 해결하였습니다. 이때 각 set에 존재하는 라인의 개수 E 에 대해 E-way set associative 방식이라고도 합니다.
아래 그림은 각 set당 두 개의 캐시 라인이 존재하는 2-way set associative 캐시를 나타낸 그림입니다:
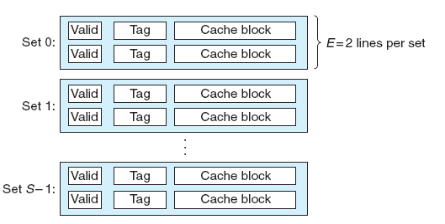
위 그림을 바탕으로, 2-way set associative 방식에서 원하는 데이터를 찾는 과정을 살펴보겠습니다:
-
Set selection: Direct mapping 방식과 동일하게, set 비트를 통해 블록이 들어갈 set을 탐색합니다.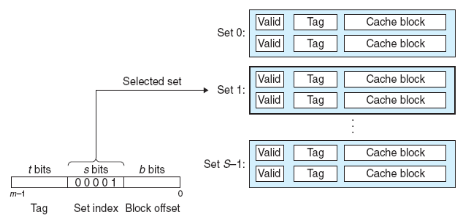
2-way set associative 캐시에서의 set 찾기. 출처: Computer Systems a Programmer's Perspective (3rd Edition) -
Line matching: Direct mapped 캐시와는 다르게, 여기서는 원하는 데이터를 찾기 위해 하나의 set에 있는 여러 캐시 라인의 tag와 valid 비트를 따져보아야 합니다. 만약 유효 비트가 1이고 태그가 일치하는 캐시 라인을 찾은 경우(즉, 캐시 히트), direct mapped 캐시와 같이 해당 라인의 블록에서 블록 오프셋 비트 b를 이용하여 데이터를 찾습니다. 하지만 만약 캐시 미스가 발생하면 아래 계층의 메모리로 가서 블록을 가져오는데, 이때 블록을 어느 캐시 라인에 넣어야 하는가? 에 관한 문제가 있습니다. 물론 비어있는 캐시 라인이 있다면 거기다 넣으면 되겠지만, 그렇지 않다면 반드시 어떤 한 라인을 선택하여 기존에 존재하는 데이터를 쫓아내고 새로 채워 넣어야 합니다. 이에 관해선 잠시 후에 살펴보겠습니다.
2-way set associative 캐시에서의 라인 매칭. 출처: Computer Systems a Programmer's Perspective (3rd Edition)
Fully Associative
이 방법은 E-way set associative 방법의 일종으로서, 하나의 set만 존재하고 이 set안에 모든 캐시 라인이 들어있는 방법입니다:
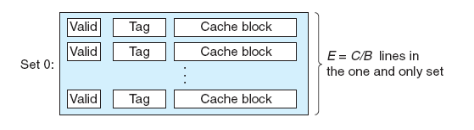
위 그림을 바탕으로, fully associative 방식에서 원하는 데이터를 찾는 과정을 살펴보겠습니다:
-
Set selection: 여기서는 set이 오직 하나밖에 없으므로, set 비트가 존재하지 않습니다! 😮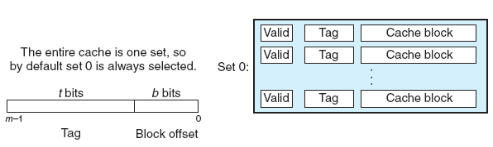
Fully Associative 캐시에서의 set 선택. 출처: Computer Systems a Programmer's Perspective (3rd Edition) -
Line matching: set associative 구조와 동일합니다.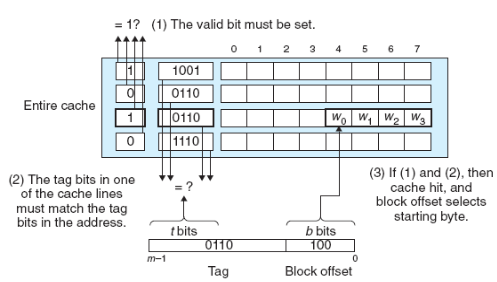
Fully Associative 캐시에서의 라인 매칭. 출처: Computer Systems a Programmer's Perspective (3rd Edition)
앞선 3가지 캐시 구조에서, set을 비교할 땐 decoder를 이용하여 비교하고 태그를 비교할 땐 태그를 비교할 때 주로 XNOR 게이트를 이용하여 메모리 주소의 태그 비트와 캐시 라인에 저장된 태그가 동일한지 비교합니다. 이때 각 라인을 하나씩 순차적으로 비교하면 비교하는 데 시간이 너무 오래걸리므로, 일반적으로 라인 개수만큼의 XNOR 게이트를 두고 병렬로 비교하는 방식을 사용합니다.
Direct mapped 방식이나 E-way set associative 방식의 경우, 각 set에 존재하는 라인 개수만큼의 XNOR 게이트를 마련하면 되지만 fully associative 방식의 경우 set이 하나밖에 없기 때문에 캐시 메모리에 존재하는 모든 라인 수만큼의 XNOR 게이트를 마련해야 합니다.
이 때문에 fully associative 방식은 decoder를 이용한 set 비교를 할 필요가 없으므로 다른 방식에 비해 속도가 빠르다는 장점이 있지만, 캐시 메모리에 존재하는 전체 라인 수만큼 XNOR 게이트를 마련해야 하므로 하드웨어의 크기가 커지고 비싸진다는 단점이 있습니다.
교체 정책(Replacement Policy)
앞서 살펴본 것처럼 캐시 미스가 발생하여 새로운 블록을 추가해야 하는 경우, 어떤 캐시 라인을 제거할 것인지에 관한 문제가 있습니다.
Direct-mapped 캐시는 각 set당 캐시 라인이 하나밖에 없으므로 해당 캐시 라인을 제거하고 새 블록을 추가하면 됩니다. 하지만 associative 방식의 경우, set 내에 2개 이상의 캐시 라인이 존재하므로 어떤 캐시 라인을 제거할 것인가에 대해 고민해 봐야 하는데 이를 결정하는 것이 교체 정책, 혹은 교체 알고리즘입니다.
이때 교체를 빠르게 수행해야 하므로 교체 알고리즘은 주로 하드웨어 수준에서 구현되는데, 흔히 알려진 교체 알고리즘을 간략히 살펴봅시다.
LRU(Least Recently Used)
가장 최근에 사용하지 않은 캐시 라인을 제거하는 방식입니다. 사실 미래를 내다보고 가장 오랫동안 사용하지 않을 캐시 라인을 제거하는 것이 이상적인 방법이겠지만, 미래를 내다볼 순 없으니 대신 과거를 살펴보는 방식이라고 할 수 있습니다.
이 방법은 캐시의 지역성에 근거를 두고 있는데, 참조 지역성 원리에 따르면 최근에 참조한 데이터는 가까운 미래에 다시 참조할 가능성이 높으므로, 반대로 생각해서 가장 오랫동안 사용되지 않았던 데이터는 앞으로도 사용될 가능성이 적다고 여기고 해당 데이터를 제거하는 방식입니다.
FIFO(First In First Out)
가장 오랫동안 캐시에 머물렀던 라인을 제거하는 방식입니다.
LFU(Least Frequently Used)
가장 적게 참조된 라인을 제거하는 방식입니다.
Random
말 그대로, 제거할 라인을 랜덤하게 선택하는 방식입니다.
Write Policy
마지막으로, 캐시의 쓰기 동작을 한번 살펴보겠습니다. 현재 쓰고자 하는 블록이 캐시에 존재하는 경우를 write hit, 쓰고자 하는 블록이 캐시에 없는 경우를 write miss라고 합니다.
Write Through
write hit이 발생했을 때, 현재 레벨 (캐시) 메모리의 블록을 수정하고, 곧바로 아래 레벨 (캐시) 메모리의 블록도 수정하는 방법입니다. 단순하고 캐시 일관성을 비교적 잘 유지할 수 있다는 장점이 있지만, 매번 쓰기를 할 때마다 버스 트래픽 오버헤드가 발생함으로 인해 속도가 느리다는 단점이 있습니다.
Write Back
write hit이 발생했을 때, 일단은 현재 레벨 (캐시) 메모리의 블록만 수정해놓고 해당 블록의 내용이 교체 정책에 의해 쫓겨날 때 아래 레벨 (캐시) 메모리에 변경 사항을 반영하는 방식입니다.
캐시의 지역성으로 인해 트래픽을 현저하게 감소시킬 수 있으나, 각 라인마다 블록이 수정되었는지를 기록하는 dirty bit (or, modify bit)를 따로 사용해야 합니다. 다시 말해, 블록이 교체되었을 때 dirty bit가 1인 블록만 아래 레벨의 메모리에 내용을 반영하도록 하는 방식입니다.
Write Allocate
write miss가 발생했을 때, 아래 레벨의 메모리에서 해당 블록을 가져온 다음 write 하는 방식이다. 공간 지역성을 활용하는 방식이며, 매 순간 write miss가 발생할 때마다 아래 레벨의 메모리에서 블록을 가져옴으로 인해 속도가 느리다는 단점이 존재합니다.
No Write Allocate
write allocate와 반대로, 아래 레벨의 메모리에 있는 블록만 수정하고 수정된 블록을 현재 레벨 (캐시) 메모리에 가져오지 않는 방식입니다.
일반적으로, write through와 no write allocate 방식을 같이 사용하고, write back과 write allocate 방식을 조합해서 사용합니다.